Auswertung der globalen Temperaturdaten mit statistischen Methoden


Er sagte vor den US – Kongress-Persönlichkeiten [Congresspersonages], oder wie man diese Klasse von Politicritters sonst nennen mag, Folgendes:
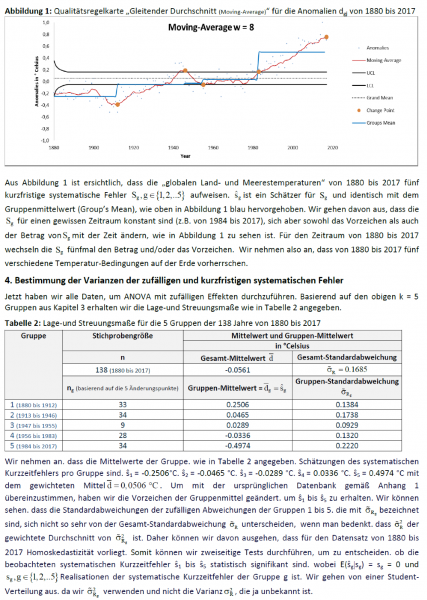
Die beobachtete Erwärmung während der letzten 30 Jahre, das heißt seit wir genaue Messungen der atmosphärischen Zusammensetzung haben, wird durch die dicke schwarze Linie in dieser Graphik dargestellt. Die Erwärmung beträgt fast 0,4°C bis 1987 relativ zur Klimatologie. Das ist der definierte Zeitraum von 30 Jahren, 1950 bis 1980, und die Erwärmung beträgt tatsächlich im Jahre 1988 über 0,4°C. Die Wahrscheinlichkeit einer zufälligen Erwärmung dieser Größenordnung liegt bei etwa 1%. Mit 99% Vertrauen können wir also feststellen, dass die Erwärmung während dieses Zeitraumes ein realer Erwärmungstrend ist.
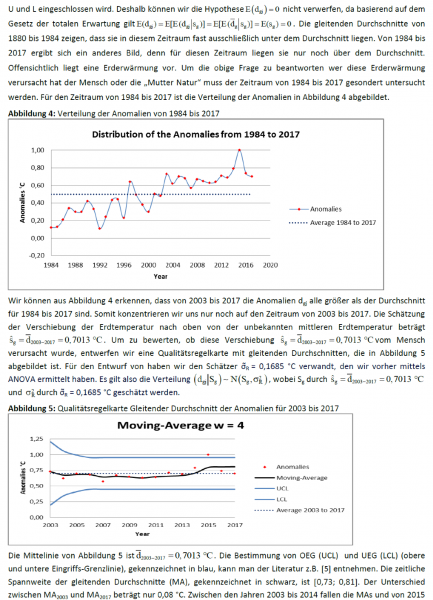
Hier ist nun diese erwähnte Graphik:
 Nun ist es entweder mein Fluch oder mein Segen, mit etwas gesegnet zu sein, was ich „einen Riecher für faule Zahlen“ nenne. Dieses ulkige Talent hat vermutlich seine Ursache im Gebrauch eines Rechenschiebers während meiner Schulzeit. Ein Rechenschieber hat keine Dezimalstellen. Falls sich also darauf das Ergebnis 3141 zeig, muss man sich überlegen, ob es 314,1 oder 3,141 oder 0,003141 oder 31410 ist. Nachdem ich dies Jahre lang gemacht hatte, entwickelte sich bei mir ein immanenter Sinn zu erkennen, ob ein Ergebnis vernünftig ist oder nicht.
Nun ist es entweder mein Fluch oder mein Segen, mit etwas gesegnet zu sein, was ich „einen Riecher für faule Zahlen“ nenne. Dieses ulkige Talent hat vermutlich seine Ursache im Gebrauch eines Rechenschiebers während meiner Schulzeit. Ein Rechenschieber hat keine Dezimalstellen. Falls sich also darauf das Ergebnis 3141 zeig, muss man sich überlegen, ob es 314,1 oder 3,141 oder 0,003141 oder 31410 ist. Nachdem ich dies Jahre lang gemacht hatte, entwickelte sich bei mir ein immanenter Sinn zu erkennen, ob ein Ergebnis vernünftig ist oder nicht.
Als mir also Hansens obiges Zitat vor Augen kam, dachte ich gleich „Unsinn! Faule Zahlen!“ Ich schaute genauer hin und fand … die Zahlen waren noch fauler.
Als erstes versuchte ich, Hansens Zahlen zu reproduzieren. Unglücklicherweise hatte er die alte GISS-Temperaturaufzeichnung herangezogen, erstellt bevor sie so adjustiert worden sind, wie sie sich heute darstellen. Sein Statement lautete auf „fast 0,4°C Erwärmung bis 1987“. Aber in den aktuellen GISS-Daten fand ich noch etwas mehr Erwärmung, nämlich 0,5°C
Nun gut. Dann machte ich daran, obigen Datensatz zu digitalisieren, um mit den Daten von Dr. Hansen arbeiten zu können. Dabei stellte sich heraus dass diese fast 0,4°C Erwärmung bis 1987 tatsächlich 0,32°C betrug. Man kann dies obiger Graphik entnehmen. Hmm … Dr. Hansens Alarmismus ist unstillbar. Man beachte auch, dass Dr. Hansen die Graphik zusammengestückelt hat und das „Jahres“-Mittel des Jahres 1988 diskutierte, obwohl er zu jenem Zeitpunkt erst wenige Monate mit Daten von 1988 hatte … schlechter Wissenschaftler, keine Cookies. Vergleiche sollten zwischen Äpfeln und Äpfeln erfolgen.
Als Nächstes ist da seine Behauptung, dass die Wahrscheinlichkeit dafür, dass die Erwärmung ein Zufallsereignis ist, 1 zu 100 beträgt. Das bedeutet, dass seine Temperatur 1987 um 2,6 Standardabweichungen wärmer sein sollte als das Mittel 1951 bis 1980. Aber noch einmal, Dr. Hansen übertreibt – es sind lediglich 2,5 Standardabweichungen vom Mittel, nicht 2,6.
Allerdings ist das nicht das eigentliche Problem. Gemeinsam mit den meisten Temperatur-Datensätzen bzgl. Klima hat Hansen den GISS-Datensatz als einen hohen „Hurst-Exponenten“ verwendet. Dies bedeutet, dass der GISS-Datensatz etwas aufweist, was „natürlich trendig“ [naturally trendy] genannt wird. In derartigen Datensätzen treten große Schwingungen viel häufiger auf als in rein zufälligen Datensätzen.
Wie viel häufiger? Nun, das können wir tatsächlich überprüfen. Er verglich den 30-jährigen „Klimatologie“-Zeitraum 1951 bis 1980 mit dem Jahr 1987. Ich machte also genau das Gleiche, aber mit anderen Jahren, d. h. ich verglich den 30-jährigen Zeitraum 1901 bis 1930 mit dem Jahr 1937, um zu sehen, wie ungewöhnlich jenes Ergebnis ist, und so weiter.
Macht man das für alle möglichen Jahre im GISS-Datensatz 1988, ergibt sich, dass der Abstand von 2,5 Standardabweichungen vom klimatologischen Mittel keineswegs ungewöhnlich ist. Es kommt in einem von 14 Jahren vor.
Und führt man die gleiche Analyse des gesamten GISS-Datensatzes bis heute durch, ist dies sogar noch normaler. In der historischen Aufzeichnung war es in einem von 7 Jahren aufgetreten. Fazit: Hansens „1 Prozent Wahrscheinlichkeit“, dass die Temperatur 1988 ungewöhnlich war, betrug in Wirklichkeit 14 Prozent Wahrscheinlichkeit … eine weitere alarmistische Fehlinterpretation – keine Überraschung angesichts der Quelle.
Schlussfolgerungen des ersten Teiles:
Betrachtet man die Wärme des Jahres 1987, welche um 2,5 Standardabweichungen wärmer ausgefallen war als das 30-jährige klimatologische Mittel, behauptete Hansen, dass die Wahrscheinlichkeit einer zufälligen Erwärmung in dieser Größenordnung etwa 1 Prozent beträgt.
In Wirklichkeit tritt eine derartige Erwärmung in der von im herangezogenen Aufzeichnung etwa alle 14 Jahre auf … und in der GISS-Aufzeichnung bis heute sogar alle 7 Jahre. Die Wahrscheinlichkeit einer zufälligen Erwärmung dieser Größenordnung in der GISS-Temperaturaufzeichnung beträgt also nicht 1 Prozent, sondern liegt zwischen 7 und 14 Prozent … was bedeutet, dass dies in keiner Weise ungewöhnlich ist.
Zweiter Teil
Im Verlauf der Recherchen zum ersten Teil dieses Beitrags erkannte ich, warum so viel darüber diskutiert wird, ob Hansens Prophezeiungen richtig oder falsch waren.Das Problem ist, dass wir in einem Zeitalter leben, dass der erfinderischste und talentierteste Cartoonist Josh das „Adjustocene“ nennt…
 Das weitere Problem ist, dass Dr. James Hansens nicht nur der Knabe ist, der 1988 die alarmistischen Prophezeiungen abgab. Er ist auch derjenige, der verantwortlich war für die GISS-Temperaturaufzeichnung, von der er lange gehofft hatte, dass sie seine Prophezeiungen wahr werden lässt.
Das weitere Problem ist, dass Dr. James Hansens nicht nur der Knabe ist, der 1988 die alarmistischen Prophezeiungen abgab. Er ist auch derjenige, der verantwortlich war für die GISS-Temperaturaufzeichnung, von der er lange gehofft hatte, dass sie seine Prophezeiungen wahr werden lässt.
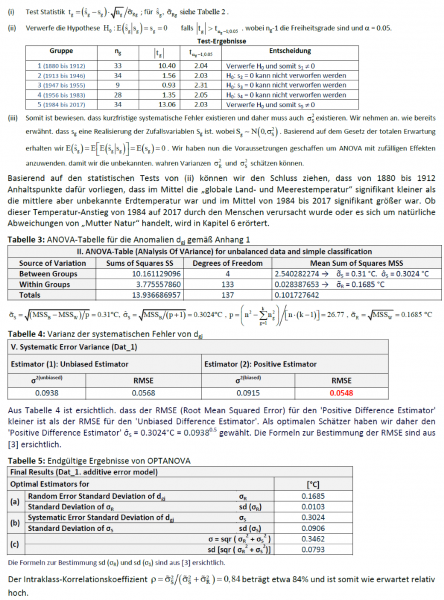
Hier sind also die Änderungen zwischen der Version der GISS-Temperaturaufzeichnungen, die Hansen 1988 herangezogen hatte, und die Version derselben aus dem Jahr 2018:
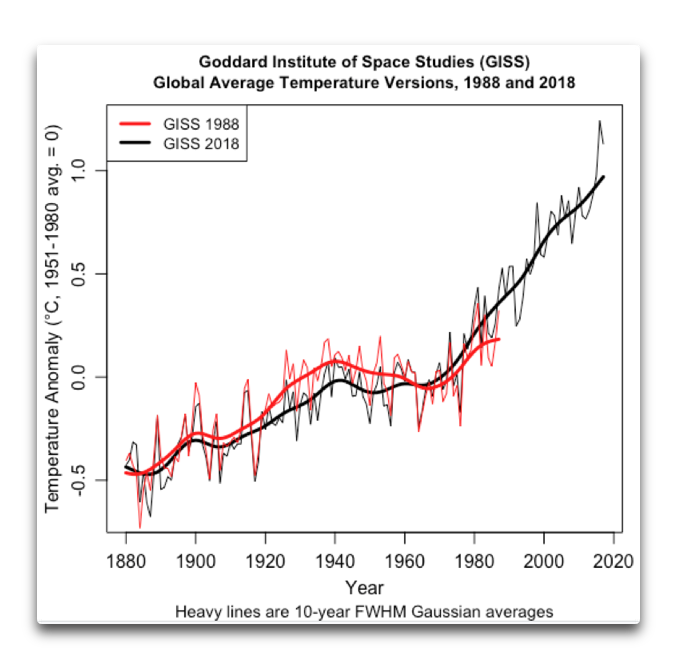
Meine Güte, das sind ein paar signifikante Änderungen. In der alten GISS-Aufzeichnung (rot) waren die Jahre 1920 bis 1950 viel wärmer als in der neuen Aufzeichnung. Folge: der alten Aufzeichnung zufolge kühlte es sich ziemlich radikal ab von etwa 1940 bis 1970 … aber in der neuen Aufzeichnung ist davon nichts mehr zu sehen.
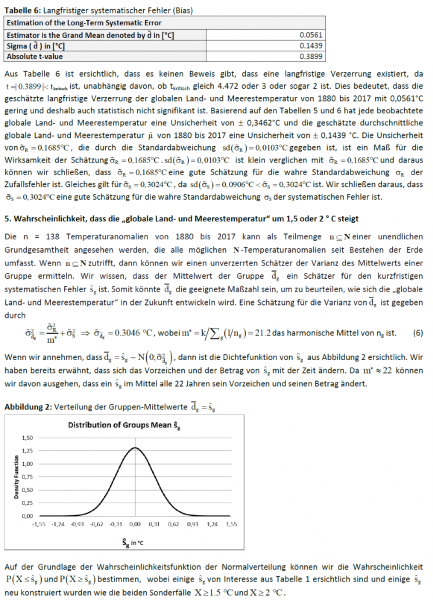
Und es wird nicht besser, wenn wir eine andere aktuelle Aufzeichnung dem Mix hinzufügen. Hier ist der HadCRUT-Datensatz der globalen mittleren Temperatur des Hadley Centers:
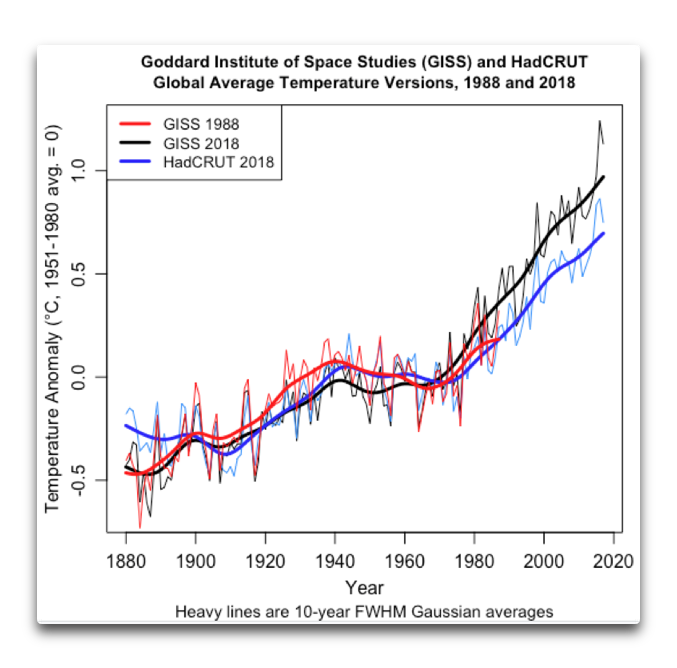 Man beachte, dass HadCRUT (blau) den gleichen Temperaturrückgang von 1940 bis 1970 zeigt, der auch in der Version 1988 der GISS-Temperaturaufzeichnung auftaucht (rot). Auf den Punkt gebracht: Die Divergenz nach 1988 zwischen den Aufzeichnungen des HadCRUT und vom GISS sind groß genug, um es unmöglich zu machen zu bestimmen, ob Hansen recht oder unrecht hatte. Der Gesamttrend in den Daten GISS 2018 ist um etwa 40% größer als in den HadCRUT-Daten. Jeder bekommt also die Antwort die er haben will – er muss nur den richtigen Datensatz wählen.
Man beachte, dass HadCRUT (blau) den gleichen Temperaturrückgang von 1940 bis 1970 zeigt, der auch in der Version 1988 der GISS-Temperaturaufzeichnung auftaucht (rot). Auf den Punkt gebracht: Die Divergenz nach 1988 zwischen den Aufzeichnungen des HadCRUT und vom GISS sind groß genug, um es unmöglich zu machen zu bestimmen, ob Hansen recht oder unrecht hatte. Der Gesamttrend in den Daten GISS 2018 ist um etwa 40% größer als in den HadCRUT-Daten. Jeder bekommt also die Antwort die er haben will – er muss nur den richtigen Datensatz wählen.
Schlussfolgerungen des zweiten Teiles:
Abhängig vom gewählten Datensatz kann jeder zweigen, dass Dr. Hansens Prophezeiungen richtig oder falsch waren … die perfekten Prophezeiungen nach Art von Schrödingers Katze*.
[*Wer wissen will, was sich dahinter verbirgt, schaue hier. Anm. d. Übers.]
Und zum Schluss, ein Nebenaspekt: Was macht ein „Institute of Space Studies“, wenn es das Klima untersucht? Ich habe vorher schon von „mission creep“ (?) gehört, aber das hier ist mehr als mission creep, das ist eine außerirdische Bewegung. Ich weiß nicht, ob die Goddard-Leute es gemerkt haben, aber im Weltraum gibt es kein Klima … wie wäre es, wenn sie zurückkehren zu der Erforschung der Myriaden interessanter Dinge, welche sich im Weltraum ereignen, und die Klimaforschung weniger alarmistischen Personen überlassen?
Link: https://wattsupwiththat.com/2018/06/30/dr-hansens-statistics/
Übersetzt von Chris Frey EIKE

Man muss diese Studie buchstäblich als eine Begutachtung der Daten auf statistischer Grundlage verstehen. Ich habe eine Statistik entwickelt, um die Daten zu quantifizieren, einzuordnen und zu kategorisieren. Meine Statistik enthält keine Ecken und Kanten, sondern ist einfach die Gesamtänderung der Temperatur zwischen den ersten und den letzten 10 Jahren des Zeitraumes 1900 bis 2011 für jede Station.
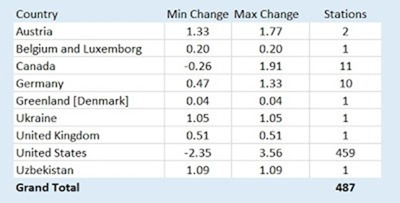
Hier folgt zunächst eine Auflistung der Länder, welche die geringste bzw. die stärkste Gesamtänderung zeigen sowie die Anzahl der Stationen pro Land:
Dies ist ein altmodisches Histogramm, welches die Stationen in der Reihenfolge hinsichtlich der Gesamt-Temperatur listet. Diese zeigt die Daten in einer Glockenkurve. Die zugrunde liegende Verteilung ist sehr ähnlich einer Normalverteilung. Das bedeutet, dass die Anwendung normaler Verfahren sehr vernünftige Abschätzungen ergeben wird. Für einen Statistiker ist dies bedeutsam. Allerdings braucht man kein Hintergrundwissen in Statistik, um das Folgende zu verstehen.
Der Wert der Mittellinie liegt zwischen -0,5° und +0,5°. Die Anzahl der insgesamt eine Abkühlung zeigenden Stationen macht 40% aus. Etwas weniger als 60% zeigen eine Erwärmung. Die absolute Änderung ist an 74,6% aller Stationen statistisch nicht signifikant.
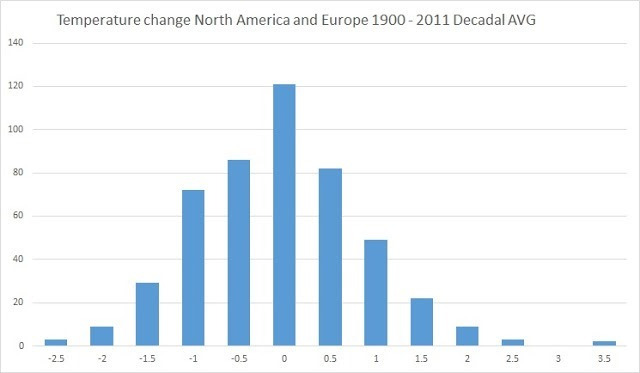
Die folgende Graphik zeigt eine normalisierte Darstellung jeder Kategorie: Keine signifikante Änderung, signifikante Erwärmung und signifikante Abkühlung. Der Graph zeigt gleitende Mittel über 10 Jahre. Jeder Plot ist so normalisiert worden, dass das Mittel des Zeitraumes 1900 bis 1910 Null beträgt.
Obwohl die Steigung jedes Plots signifikant unterschiedlich ist, ist der Verlauf der Kurven nahezu identisch. Eine Zufallssammlung individueller Stationsdaten zeigt, dass die Bedingungen für jede Station innerhalb der Bandbreite wahr bleiben. Zum Beispiel zeigt die dänische Grönland-Station, dass das Mittel der Jahre 1990 bis 2000 gleich ist dem Mittel von 1930 bis 1940.
Kurzfristige Änderungen wie etwa die Erwärmung bis in die dreißiger Jahre, sind bei einer Mehrheit der Stationen eindeutig erkennbar. Andere Beispiele hiervon sind der Temperatursprung der vierziger Jahre, die Abkühlung nach 1950 und der Temperatursprung zum Ende der neunziger Jahre.
Langfristige Änderungen variieren signifikant.
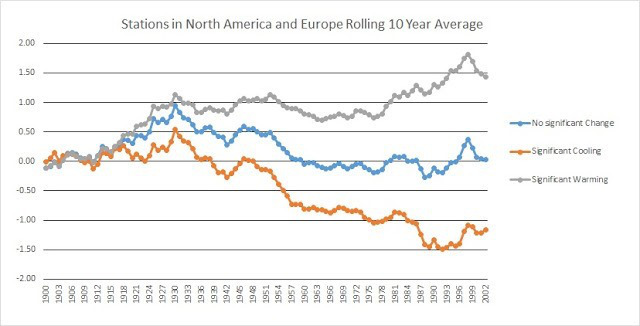
Aus dieser Analyse lässt sich eine ganze Reihe von Schlussfolgerungen ablesen:
● Es gibt keinen statistisch signifikanten Unterschied zwischen Nordamerika und Europa. Die eine signifikante Abkühlung zeigenden Stationen machen nur 8% der Gesamtzahl aus. Bei dieser Statistik wäre die erwartete Anzahl von 17 eine Abkühlung zeigenden Stationen nur eine. Die Anzahl der eine signifikante Erwärmung zeigenden Stationen wäre 3. Vom Standpunkt der Stichprobenmenge aus sind 17 keine ausreichend große Stichprobe, um genaue Schätzungen zu erhalten.
● Kurzfristige Änderungen, welche Stationen von Kanada über die USA bis Europa erkennbar sind, sind möglicherweise hemisphärische Änderungen. Allerdings gibt es keinen Hinweis darauf, dass diese Änderungen global sind, gibt es doch keine Anzeichen ähnlicher Änderungen in Australien. Tatsächlich unterscheidet sich die Gesamtverteilung in Australien offensichtlich von dem, was wir hier sehen.
● Die Beweise zeigen eindeutig, dass die große Variation an den Gesamt-Temperaturtrends entweder regionalen oder lokalen Faktoren geschuldet ist. Wie in der Datentabelle oben gezeigt stammen alle Extreme dieser Variation aus den USA. Wie schon erwähnt reicht die Stichprobenmenge aus Europa einfach nicht aus, um genaue Schätzungen von Bedingungen mit kleiner Prozentzahl zu erhalten.
● Weiter zeigt sich eindeutig, dass die meisten Differenzen der Gesamt-Temperaturänderung lokalen Faktoren geschuldet sind. In den USA erkennt man, dass extreme Erwärmung allgemein auf Gebiete mit starker Zunahme der Bevölkerung, Wachstum oder hohem Entwicklungsniveau beschränkt sind. Große Städte wie San Diego, Washington DC und Phoenix folgen dem verlauf signifikanter Änderung. Das gilt auch für Flughäfen. Allerdings folgen Städte wie New Orleans, St. Louis, El Paso und Charleston der Verteilung ohne signifikante Änderung.
Schlussfolgerung: Der Fall globale Erwärmung auf der Grundlage der verfügbaren langzeitlichen Daten ist sehr schwach. Es gibt Hinweise, dass eine hemisphärische Verteilung existiert. Weitere Beweise zeigen, dass es sich um eine zyklische Verteilung handelt, die in lokalisierten Temperaturspitzen während der dreißiger und der neunziger Jahre zum Ausdruck kommt. Allerdings scheinen Veränderungen der lokalen Umstände an den Stationen infolge menschlicher Entwicklungen der wichtigste Faktor zu sein, welcher die Gesamt-Temperaturänderungen beeinflusst. Extreme Erwärmungstrends sind fast mit Sicherheit auf vom Menschen vorgenommene lokale Änderungen zurückzuführen.
Unklar bis zu diesem Punkt ist die Bedeutung geringerer, vom Menschen induzierter Änderungen. Um dies abzuschätzen, bedarf es der Untersuchung individueller Stationsorte, um eine signifikante Stichprobe von Stationen zu erhalten, die keine Änderung zeigen. Unglücklicherweise hat man sich in den USA, in Kanada und Europa nicht einmal ansatzweise dieser Art von Informationen verschrieben wie in Australien. Ich muss zugeben, dass die Australier exzellente Arbeit geleistet haben, um Stationsinformationen verfügbar zu machen. Mit den aktuellen Koordinaten der tatsächlichen Teststationen war dies einfach. Ich schaute einfach bei Google Maps und war in der Lage, den Aufstellort und die Umgebung zu begutachten.
Mark Fife holds a BS in mathematics and has worked as a Quality Engineer in manufacturing for the past 30 years.
Übersetzt von Chris Frey EIKE
In den Kommentaren zu meinen letzten Beiträgen über Tidenmessgeräte erhob sich die Frage der Beständigkeit der Unsicherheit in den Original-Messungen. Hier folgen die Fragen, die zu beantworten ich mit diesem Beitrag versuchen möchte:
Falls Originalmessungen bis auf eine Unsicherheit von +/- X (irgendein Wert in irgendeiner Einheit) durchgeführt werden, überträgt sich dann die Unsicherheit der Originalmessung auf einen oder alle Mittelwerte dieser Messungen?
Sorgt die Durchführung weiterer Messungen bis auf den gleichen Grad Unsicherheit genau die Berechnung noch genauerer Mittelwerte?
Meine Haltung in diesem Beitrag ist Folgende:
Falls jede Messung nur auf ± 2 cm genau ist, dann kann das monatliche Mittel nicht NOCH genauer sein – es muss die gleiche Bandbreite von Fehlern/Unsicherheiten enthalten wie die Originalmessungen, aus denen das Mittel gebildet worden ist. Die Mittelung bringt keine Erhöhung der Genauigkeit.
Es wäre untertrieben zu sagen, dass es sehr viel Uneinigkeit von einigen Statistikern und jenen mit einer klassischen statistischen Ausbildung gab.
Ich werde mich nicht über das Thema Präzision oder Präzision von Mittelwerten auslassen. Es gibt dazu eine gute Diskussion bei Wikipedia: Accuracy and precision.
Gegenstand meiner Bedenken hier ist diese reine Trivial-Genauigkeit [vanilla accuracy]: „Genauigkeit einer Messung ist der Grad, wie nahe Messungen von bestimmter Anzahl an dem wahren Wert jener Quantität liegt“. (,Wahrer Wert‘ bedeutet hier den tatsächlichen Wert in der realen Welt – nicht irgendein kognitives Konstrukt desselben).
Der allgemeine Standpunkt der Statistiker wird in diesem Kommentar zusammengefasst:
„Die Aussage, dass die Genauigkeit des mittleren Meeresspiegels an einer Stelle nicht verbessert wird durch die Durchführung vieler Messungen über einen verlängerten Zeitraum ist lachhaft und legt ein fundamentales Fehlen von Verständnis der physikalischen Wissenschaft an den Tag“.
Ich gebe zu, dass ich frisch von der Universität einmal diesem Standpunkt zugestimmt habe. Und zwar bis ich einem berühmten Statistiker die gleiche Frage vorlegte. Sofort und gründlich wurde ich mit einer Reihe von Hausaufgaben konfrontiert, womit ich mir selbst beweisen sollte, dass der Gedanke in vielfacher Hinsicht unrichtig ist.
Erstes Beispiel:
Beginnen wir mit einem einfachen Beispiel über Temperaturen. Temperaturen in den USA werden in ganzen Grad Fahrenheit gemessen und aufgezeichnet. (Fragen Sie mich nicht, warum wir nicht den wissenschaftlichen Standard benutzen. Ich weiß es nämlich nicht). Diese Aufzeichnungen in ganzen Grad Fahrenheit werden dann mittels eines Rechners in Grad Celsius konvertiert, und zwar bis zur ersten Dezimalstelle, also beispielsweise 15,6°C.
Dies bedeutet, dass jede und alle Temperaturen zwischen beispielsweise 72,5°F und 71,5°F als 72°F aufgezeichnet werden. (In der Praxis wird die eine oder andere Messung mit X,5 ausgesondert und die anderen ab- oder aufgerundet). Folglich bedeutet eine amtliche Temperaturaufzeichnung vom Battery Park um 12 Uhr mittags von „72°F“ in der realen Welt, dass die Temperatur mittels Messung in der Bandbreite zwischen 71,5°F und 72,5°F liegt – mit anderen Worten, die präsentierte Zahl repräsentiert eine Bandbreite von 1°F.
In der wissenschaftlichen Literatur könnten wir diesen Umstand in der Schreibweise 72 +/- 0.5 °F wiederfinden. Oftmals wird dies dann als eine Art „Vertrauensintervall“, „Fehlerbalken“ oder Standardabweichung missverstanden.
In diesem spezifischen Beispiel einer Temperaturmessung ist es nichts von diesen Dingen. Es ist einfach eine Form von Stenogramm für das tatsächliche Messverfahren, welches jedes Grad Bandbreite von Temperatur als eine einzelne ganze Zahl repräsentiert – wenn die Bedeutung in der realen Welt lautet „eine Temperatur mit einer Bandbreite von 0,5 Grad über oder unter der präsentierten ganzen Zahl“.
Jede Differenz zur tatsächlichen Temperatur über oder unter der präsentierten ganzen Zahl ist kein Fehler. Diese Abweichungen sind keine „Zufallsfehler“ und sind nicht „normalverteilt“.
Noch einmal zur Betonung: Die ganze Zahl einer präsentierten Temperatur an irgendeiner Stelle zu irgendeiner Zeit ist ein Kürzel für eine ein Grad große Bandbreite tatsächlicher Temperaturen, die obwohl laut Messung unterschiedlich in Gestalt der gleichen ganzen Zahl gemeldet werden. Visuell:
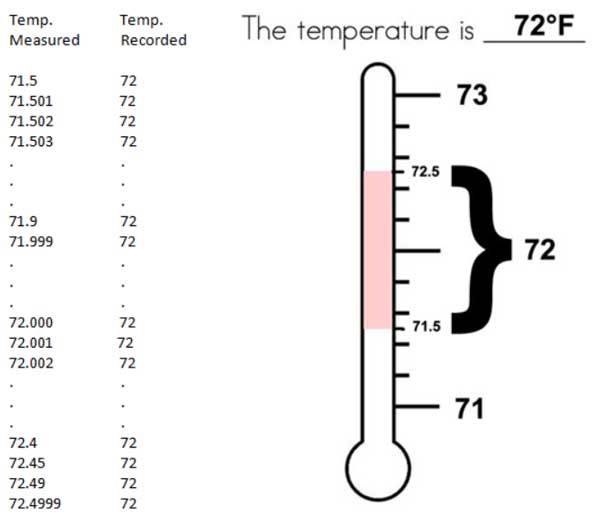
Obwohl in der Praxis die Temperaturen nur in ganzen Zahlen gemeldet werden, ändern sich die Temperaturen in der realen Welt nicht in Schritten von einem ganzen Grad – 72, 73, 74, 72, 71 usw. Temperatur ist eine kontinuierliche Variable. Und nicht nur das, sie ist eine sich ständig ändernde Variable. Wenn man Temperatur einmal um 11:00 und dann um 11:01 misst, misst man zwei unterschiedliche Quantitäten; die Messungen erfolgen unabhängig voneinander. Außerdem ist einer und sind alle Werte innerhalb der Bandbreite gleich wahrscheinlich – die Natur „bevorzugt“ keine Temperaturen, welche näher an der ganzen Zahl liegen.
(Anmerkung: In den USA werden ganze Grad Fahrenheit in Grad Celsius bis zur ersten Stelle nach dem Komma gerundet. 72°F werden konvertiert und ebenfalls aufgezeichnet als 22,2°C. Die Natur bevorzugt auch nicht Temperaturen, die näher an einem Zehntelgrad Celsius liegen).
Während es gegenwärtig Praxis ist, eine ganze Zahl zu melden, um die Bandbreite von ,ganzer Zahl plus ein halbes Grad und ganzer Zahl minus ein halbes Grad‘ zu repräsentieren, könnte diese Praxis auch irgendeine andere Notation sein. Es könnte auch einfach sein, dass die gemeldete ganze Zahl alle Temperaturen von der ganzen Zahl bis zur nächsten ganzen Zahl repräsentieren soll, dass also 71 bedeutet „irgendeine Temperatur von 71 bis 72“. Das gegenwärtige System der Verwendung der ganzen Zahl in der Mitte ist besser, weil die gemeldete ganze Zahl in der Mitte der sie repräsentierenden Bandbreite liegt. Allerdings ist dies einfach misszuverstehen, wenn es als 72 +/- 0.5 daherkommt.
Weil Temperatur eine kontinuierliche Variable ist, sind Abweichungen von der ganzen Zahl nicht einmal „Abweichungen“ – sie sind einfach die in Grad Fahrenheit gemessenen Temperatur, welche normalerweise durch den Dezimalanteil repräsentiert wird, welcher der Notation der ganzen Gradzahl folgen würde – der „x.4999“te Teil von 72,4999°F. Diese Dezimalanteile sind keine Fehler, sie sind nicht gemeldete und nicht aufgezeichnete Anteile der Messung, und weil Temperatur eine kontinuierliche Variable ist, muss sie als gleichmäßig verteilt über die gesamte Skala betrachtet werden – mit anderen Worten, es sind keine, keine, keine „normalverteilten Zufallsfehler“. Der einzige Grund, warum sie unsicher sind ist, dass sie selbst bei einer Messung nicht aufgezeichnet werden.
Was passiert also jetzt, nachdem wir herausgefunden haben, dass die Mittelwerte dieser Aufzeichnungen, welche – man erinnere sich – Kürzel von Temperatur-Bandbreiten sind?
Um diese Frage zu beantworten, wollen wir ein Schulexperiment durchführen…
Wir werden das Mittel von drei ganzen Grad Temperatur finden, und zwar erhalten wir diese Temperaturen in meinem Wohnzimmer:

Wie oben diskutiert, repräsentieren diese Temperaturwerte irgendwelche der unbegrenzt variablen Temperaturen, dennoch möchte ich diese kleine Graphik erstellen:
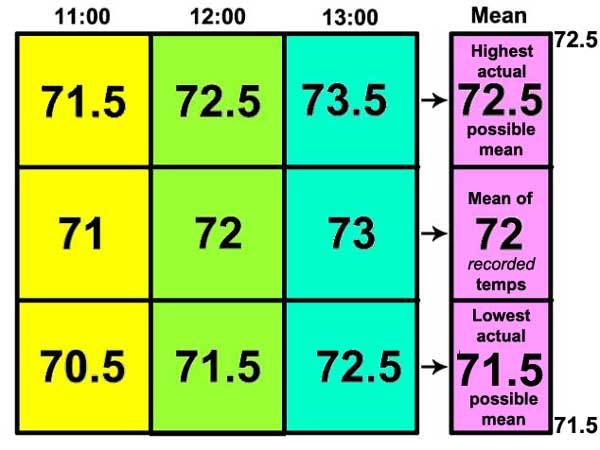
Hier erkennen wir, dass die Temperatur von jeder Stunde den höchsten Wert in der Bandbreite repräsentiert, den mittleren Wert in der Bandbreite (die gemeldete ganze Zahl) und als tiefsten Wert der Bandbreite. (Anmerkung: Wir dürfen nicht vergessen, dass es zwischen den Werten in jeder Spalte eine unendliche Anzahl von Bruchwerten gibt, die wir jetzt nur nicht zeigen). Diese Werte werden dann gemittelt – das Mittel berechnet – von links nach rechts: die höchsten Werte der drei Stunden ergeben ein Mittel von 72,5, der mittlere Wert ein Mittel von 72 und der niedrigste Wert ein Mittel von 71,5.
Das resultierende Mittel kann geschrieben werden in der Form 72 +/- 0.5, was ein Kürzel ist dafür, dass die Bandbreite von 71,5 bis 72,5 repräsentiert wird.
Die Genauigkeit des Mittels, repräsentiert in der Schreibweise +/- 0,5 ist identisch mit der Genauigkeit der Original-Messungen – sie repräsentieren beide eine Bandbreite möglicher Werte.
Anmerkung: Diese Unsicherheit stammt nicht aus der tatsächlichen instrumentellen Genauigkeit der Original-Messungen. Das ist etwas ganz anderes und muss zusätzlich zu der hier beschriebenen Genauigkeit betrachtet werden. Diese resultiert allein aus der Tatsache, dass gemessene Temperaturen als Ein-Grad-Bandbreiten dargestellt werden, wobei die Bruchteil-Informationen außen vor bleiben und für immer verloren sind, was uns mit der Unsicherheit zurücklässt – fehlendem Wissen – was die tatsächliche Messung selbst eigentlich war.
Natürlich kann die um 11:00 gemessene Temperatur 71,5; die um 12:00 gemessene 72 und die um 13:00 gemessene 72,5 betragen haben. Oder es könnte auch 70,5; 72; 73,5 gewesen sein.
Die Berechnung des Mittels zwischen den diagonal gegenüber liegenden Ecken ergibt 72 von Ecke zu Ecke. Über die Mittelpunkte ergibt sich immer noch 72.
Jedwede Kombination von höchsten, mittigen und niedrigsten Werten von jeder Stunde ergibt ein Mittel, welches zwischen 72,5 und 71,5 liegt – innerhalb der Unsicherheits-Bandbreite des Mittels.
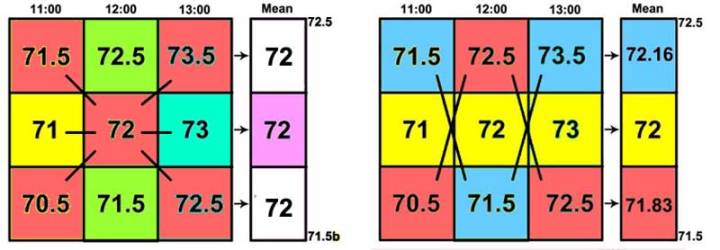
Selbst für diese vereinfachten Netze gibt es viele mögliche Kombinationen von einem Wert aus jeder Spalte. Das Mittel jedweder Kombination liegt zwischen den Werten 72,5 und 71,5.
Es gibt buchstäblich eine unendliche Anzahl potentieller Werte zwischen 72,5 und 71,5, da Temperatur eine kontinuierliche Variable für jede Stunde ist. Das Auftreten aller möglichen Werte für jede stündliche Temperatur ist gleich wahrscheinlich – folglich sind alle möglichen Werte und alle möglichen Kombinationen eines Wertes für jede Stunde in Betracht zu ziehen. Nimmt man irgendeinen möglichen Wert aus jeder Spalte mit stündlichen Messungen und mittelt diese drei, ergibt sich immer das gleiche Ergebnis – alle Mittel haben einen Wert zwischen 72,5 und 71,5, was eine Bandbreite der gleichen Größenordnung repräsentiert wie die der Original-Messungen, eine Bandbreite von einem Grad Fahrenheit.
Die Genauigkeit des Mittels entspricht genau der Genauigkeit aus den Original-Messungen – es ist in beiden Fällen eine Ein-Grad-Bandbreite. Sie wurde um keinen Deut reduziert durch das Mittelungs-Verfahren. Das kann es auch nicht.
Anmerkung: Eine mehr technische Diskussion zu diesem Thema gibt es hier und hier.
Und die Daten der Tiden-Messgeräte?
Es ist klar, dass sich die Unsicherheit bzgl. der Genauigkeit der Original-Messungen der Temperatur aus dem Umstand ergibt, dass nur ganze Grad Fahrenheit bzw. Grad Celsius bis zur ersten Dezimalstelle angegeben werden. Das ergibt folglich keine Messungen mit einem Einzelwert, sondern stattdessen Bandbreiten.
Aber was ist mit den Daten der Tide-Messgeräte? Unterscheidet sich ein einzelner gemessener Wert bis zur Präzision von Millimetern also von obigem Beispiel? Die kurze Antwort lautet NEIN, aber ich nehme nicht an, dass das allgemein akzeptiert wird.
Welche Daten werden denn nun von Tiden-Messgeräten in den USA (und in den meisten anderen entwickelten Ländern) gemessen?
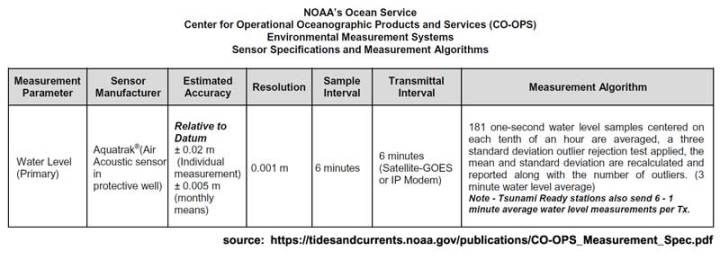
Die Geschätzte Genauigkeit wird als +/- 2 cm für individuelle Messungen angegeben, und es wird behauptet, dass diese für monatliche Mittelwerte 5 mm beträgt. Betrachten wir die Daten vom Battery-Park in New York, sehen wir etwas wie das hier:

Man beachte, dass wir laut diesem Datenblatt alle sechs Minuten (1 Zehntel-Stunde) eine Messung haben, und zwar den Wasserstand in Meter bis zum Niveau von Millimetern (4,639 m), und das „Sigma“ wird angegeben. Die Sechs-Minuten-Zahl wird folgendermaßen berechnet:
181 Eine-Sekunde-Wasserstandsmessungen zentriert um jedes Zehntel einer Stunde werden gemittelt, ein three standard deviation outlier rejection test [?] angewendet, dann werden Mittel und Standardabweichung erneut berechnet und gemeldet zusammen mit der Anzahl der Ausreißer. (3 Minuten-Wasserstandsmittel).
Um sicherzustellen, dass wir dieses Verfahren verstehen, stellte ich in einer E-Mail an @ co-ops.userservices@noaa.gov die folgende Frage:
Wenn sagen, bis zu einer Genauigkeit von +/- 2 cm meinen wir spezifisch, dass jede Messung zum tatsächlichen augenblicklichen Wasserstand außerhalb des Mess-Schachtes passt und innerhalb dieser +/- 2-cm-Bandbreite liegt.
Antwort:
Das ist korrekt! Die Genauigkeit jedes 6-minütigen Datenwertes beträgt +/- 2 cm des Wasserstandes zu jener Zeit.
(Anmerkung: In einer separaten E-Mail wurde klargestellt, dass „Sigma die Standardabweichung ist, essentiell die statistische Varianz zwischen diesen 181 1-Sekunde-Messungen“).
Frage und Antwort verifizieren, dass sowohl die 1-Sekunde-Messungen als auch der 6-Minuten-Datenwert eine Bandbreite des Wasserstandes von 4 cm, 2 cm plus oder minus vom gemeldeten Wasserstand repräsentiert.
Diese scheinbar vage Genauigkeit – jede Messung mit einer tatsächlichen Bandbreite von 4 cm – ist das Ergebnis des mechanischen Verfahrens der Mess-Apparatur, trotz der Auflösung von 1 Millimeter. Wie kommt das?
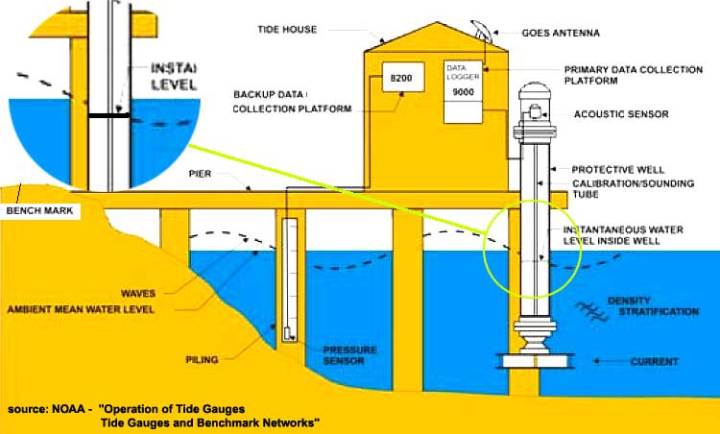
Die Illustration der NOAA des modernen Tiden-Messapparates am Battery Park zeigt den Grund. Die Blase oben links zeigt eindeutig, was während des 1-Sekunde-Intervalls der Messung passiert: Der augenblickliche Wasserstand innerhalb des Mess-Schachtes unterscheidet sich von dem außerhalb dieses Schachtes.
Diese 1-Sekunde-Ablesung wird in der „Primary data collection Platform“ gespeichert und später als Teil der 181 Messungen herangezogen, die für den gemeldeten 6-Minuten Wert gemittelt werden. Er unterscheidet sich wie illustriert von dem tatsächlichen Wasserstand außerhalb des Mess-Schachtes. Manchmal wird er niedriger, manchmal höher liegen. Der Apparat als Ganzes ist darauf ausgelegt, diese Differenz in den meisten Fällen während des 1-Sekunde-Zeitmaßstabes auf eine Bandbreite von 2 cm über oder unter dem Wasserstand im Mess-Schacht zu begrenzen – obwohl einige Ablesungen weit außerhalb dieser Bandbreite liegen und als „Ausreißer“ gelistet werden (die Regel lautet, alle 3-Sigma-Ausreißer auszusondern – aus dem Satz der 181 Ablesungen – bevor man das Mittel berechnet, welches als der 6-Minuten-Wert gemeldet wird).
Wir können nicht jede individuelle Messung als eine Messung des Wasserstandes außerhalb des Mess-Schachtes betrachten – es wird der Wasserstand innerhalb des Mess-Schachtes gemessen. Diese Im-Schacht-Messungen sind sehr genau und präzise – bis auf 1 Millimeter. Allerdings ist jede 2-Sekunde-Aufzeichnung eine mechanische Approximation des Wasserstandes außerhalb des Schachtes – also dem tatsächlichen Wasserstand im Hafen, welcher eine fortwährend sich ändernde Variable ist – spezifiziert zu der Genauigkeits-Bandbreite von +/- 2 Zentimeter. Die aufgezeichneten Messungen repräsentieren Bandbreiten von Werten. Diese Messungen enthalten keine „Fehler“ (zufällige oder andere), wenn sie sich vom tatsächlichen Wasserstand im Hafen unterscheiden. Der Wasserstand im Hafen oder im Fluss oder in der Bucht selbst ist niemals wirklich gemessen worden.
Die als „Wasserstand“ aufgezeichneten Daten sind abgeleitete Werte – und keineswegs direkte Messungen. Das Tiden-Messgerät als Messinstrument wurde so ausgerichtet, dass es Messungen innerhalb des Schachtes mit einer Genauigkeit von 2 cm, plus oder minus durchführt, welche den tatsächlichen augenblicklichen Wasserstandes außerhalb des Schachtes repräsentieren – was ja das ist, das wir messen wollen. Nach 181 Messungen innerhalb des Schachtes und dem Aussortieren jedweder Daten, die zu abwegig sind, wird der Rest der 181 Messungen gemittelt und der 6-Minuten-Wert gemeldet mit der korrekten Genauigkeits-Angabe von +/- 2 cm – der gleichen Genauigkeit also wie bei den individuellen 1-Sekunde-Messungen.
Der gemeldete Wert bezeichnet eine Werte-Bandbreite – welche immer angemessen mit jedem Wert angegeben werden muss – im Falle von Wasserständen der NOAA-Tiden-Messgeräte +/- 2 cm.
Die NOAA behauptet zu recht nicht, dass die sechs-Minuten-Aufzeichnungen, welche das Mittel von 181 1-Sekunde-Messungen sind, eine größere Genauigkeit aufweisen als die individuellen Original-Messungen.
Warum behauptet die NOAA aber dann, dass monatliche Mittelwerte bis auf +/- 5 mm genau sind? In diesen Berechnungen wird die Genauigkeit der Original-Messungen einfach komplett ignoriert, und nur die gemeldeten/aufgezeichneten Sechs-Minuten-Mittelwerte werden betrachtet (vom Autor bestätigt) – das ist der gleiche Fehler, wie er auch bei Berechnungen fast aller anderen großen Datensätze gemacht wird, indem das nicht anwendbare Gesetz Großer Zahlen [Law of Large Numbers] angewendet wird.
Genauigkeit jedoch wird, wie hier gezeigt, bestimmt durch die Genauigkeit der Original-Messungen, wenn man eine nicht statische, sich immer ändernde und kontinuierlich variable Quantität misst und dann als eine Bandbreite möglicher Werte aufzeichnet – die Bandbreite der Genauigkeit spezifiziert für das Messsystem – und die nicht durch Berechnungen von Mittelwerten verbessert werden kann.
1. Wenn numerische Werte Bandbreiten sind anstatt wahrer diskreter Werte, dann bestimmt die Größe der Bandbreite des Originalwertes (in unserem Falle die Messung) die Größe der Bandbreite jedweden nachfolgenden Mittelwertes dieser numerischen Werte.
2. Von ASOS-Stationen berechnete Temperaturen jedoch werden aufgezeichnet und als Temperaturen gemeldet mit einer Bandbreite von 1°F (0,55°C), und diese Temperaturen werden korrekt als „ganze Zahlen +/- 0,5°F“ aufgezeichnet. Die Mittelwerte dieser aufgezeichneten Temperaturen können nicht genauer sein als die Originalmessungen – weil die Aufzeichnungen der Originalmessungen selbst Bandbreiten sind. Die Mittelwerte müssen mit den gleichen +/- 0,5°F angegeben werden.
3. Gleiches gilt für die Daten von Tiden-Messapparaten, wie sie gegenwärtig gesammelt und aufgezeichnet werden. Die primäre Aufzeichnung von 6-Minuten-Werten sind trotz auf Millimeter-Genauigkeit aufgezeichneter Präzision ebenfalls Bandbreiten mit einer Original-Genauigkeit von +/- 2 Zentimetern. Dies ist die Folge des Designs und der Spezifikation des Messinstrumentes, welches das einer Art mechanisch mittelnden Systems ist. Die Mittel von Werten von Tiden-Messgeräten können nicht genauer gemacht werden als die +/- 2 cm – was weit genauer ist als notwendig zur Messung von Gezeiten und der Bestimmung eines sicheren Wasserstandes für Schiffe.
4. Wenn Original-Messungen Bandbreiten sind, sind deren Mittelwerte ebenfalls Bandbreiten von gleicher Größenordnung. Diese Tatsache darf nicht ignoriert oder missachtet werden.Tut man dies doch, erzeugt man einen falschen Eindruck von der Genauigkeit unseres numerischen Wissens. Oftmals überschattet die mathematische Präzision eines berechneten Mittels dessen reale Welt, eine weit verschwommenere Genauigkeit, was zu einer unrichtigen Signifikanz führt, welche Änderungen sehr geringer Größenordnung dieser Mittelwerte beigemessen wird.
Link: https://wattsupwiththat.com/2017/10/14/durable-original-measurement-uncertainty/
Übersetzt von Chris Frey EIKE
Sowohl das Wort als auch das Konzept „Durchschnitt“ sind in der breiten Öffentlichkeit sehr viel Verwirrung und Missverständnis unterworfen und sowohl als Wort als auch im Kontext ist eine überwältigende Menge an „lockerem Gebrauch“ auch in wissenschaftlichen Kreisen zu finden, ohne die Peer-Reviewed-Artikel in Zeitschriften und wissenschaftlichen Pressemitteilungen auszuschließen.
In Teil 1 dieser Serie lasen Sie meine Auffrischung über die Begriffsinhalte von Durchschnitten, Mittelwerten und Beispiele dazu. Entspricht Ihr Hintergrundwissen bezüglich Mathematik oder Wissenschaft dem großen Durchschnitt der Normalbürger, schlage ich vor, dass Sie einen schnellen Blick auf die Grundlagen in Teil 1 [Teil 1 hier übersetzt] und dann Teil 2 [Teil 2 hier übersetzt] werfen, bevor Sie fortfahren.
„Der Umgang mit Daten kann manchmal Verwirrung verursachen. Ein oft gemachter Fehler ist es, Durchschnittswerte zu mitteln. Dies ist oft zu sehen, wenn versucht wird, regionale Werte aus Landes- oder Kreisdaten abzuleiten“. – Was man mit Daten nicht machen darf: Durchschnittswerte zu mitteln.
„Ein Kunde hat mich heute gebeten, einen“ Durchschnitt der Durchschnittswerte „zu einigen seiner Leistungsberichten hinzuzufügen. Ich gebe offen zu, dass ein nervöses und hörbares Stöhnen meinen Lippen entrang, als ich mich in Gefahr fühlte, hilflos in die fünfte Dimension von „Simpsons Paradox“ zu stürzen – Anders ausgedrückt: Kann die Mittelung der Mittelwerte der verschiedenen Populationen den Durchschnitt der zusammengefassten Bevölkerung darstellen?“- Ist der Durchschnitt der Durchschnittswerte korrekt? (Hinweis: NEIN!)
„Simpsons Paradoxon … ist ein Phänomen der Wahrscheinlichkeiten und Statistik, in dem ein Trend in verschiedenen Datengruppen zu erkennen ist, aber verschwindet oder sich umkehrt, wenn diese Gruppen kombiniert werden. Es wird manchmal auch als Umkehrparadox oder Verschmelzungsparadox angegeben. „- siehe Wiki.de “Simpsons Paradox“
Durchschnittliche Mittelwerte sind nur gültig, wenn die Sätze von Datengruppen, Kohorten, Anzahl der Messungen – alle gleich groß sind (oder fast gleich groß) und die gleiche Anzahl von Elementen enthalten, denselben Bereich repräsentieren, die gleiche Lautstärke, die gleiche Anzahl von Patienten, die gleiche Anzahl von Meinungen und, wie bei allen Durchschnittswerten, sind die Daten selbst physisch und logisch homogen (nicht heterogen) und physisch und logisch kommensurabel (nicht inkommensurabel). [wem dies unklar ist, bitte schauen Sie noch mal Teil 1]
Zum Beispiel, hat man vier Klassen der 6. Klasse, zu denen jeweils genau 30 Schüler gehören und wollte nun die durchschnittliche Größe der Schüler finden, könnte man über es zwei Wege berechnen: 1) Durchschnitt jeder Klasse durch die Summierung der Größen der Schüler Dann finden Sie den Durchschnitt durch Division mit 30, dann summieren Sie die Mittelwerte und teilen sie durch vier, um den Gesamtdurchschnitt zu bekommen – ein Durchschnitt der Mittelwerte oder 2), Sie kombinieren alle vier Klassen zusammen für einem Satz von 120 Studenten, Summieren die Größen und teilen durch 120. Die Ergebnisse sind gleich.
Das gegenteilige Beispiel sind vier Klassen von 6. Klasse Schülern, die alle unterschiedlich groß sind und jeweils unterschiedliche Klassenstärken haben: 30, 40, 20, 60 Schüler. Die Suche nach den Mittelwerten der vier Klassen- und dann Mittelung der Mittelwerte ergibt eine Antwort – ganz anders als die Antwort, als wenn man die Größe von allen 150 Schülern summiert und dann durch 150 teilt.
Warum? Das liegt daran, dass die einzelnen Schüler der Klasse mit nur 20 Schülern und die einzelnen Schüler der Klasse von 60 Schülern unterschiedliche, ungleiche Auswirkungen auf den Gesamtdurchschnitt haben. Um für den Durchschnitt gültig zu sein, sollte jeder Schüler den 0,66ten Anteil des Gesamtdurchschnitts repräsentieren [0,66 = 1/150].
Wenn nach Klasse gemittelt wird, steht jede Klasse für 25% des Gesamtdurchschnitts. So würde jeder Schüler in der Klasse von 20 Schülern für 25% / 20 = 1,25% des Gesamtdurchschnitts zählen, während jeder Schüler in der Klasse von 60 jeweils nur für 25% / 60 = 0,416% des Gesamtdurchschnitts steht. Ebenso zählen die Schüler in den Klassen von 30 und 40 jeweils für 0,83% und 0,625%. Jeder Schüler in der kleinsten Klasse würde den Gesamtdurchschnitt doppelt so stark beeinflussen wie jeder Schüler in der größten Klasse – im Gegensatz zu dem Ideal eines jeden Schülers, der im Durchschnitt gleichberechtigt ist.
Es gibt Beispiele dafür in den ersten beiden Links für die Quoten, die in diesen Abschnitt vorgestellt wurden. (Hier und hier)
Für unsere Leser in Indiana (das ist einer der Staaten in den USA), konnten wir das beim Pro-Kopf Einkommen im Indianapolis Metropol Bereich erkennen:
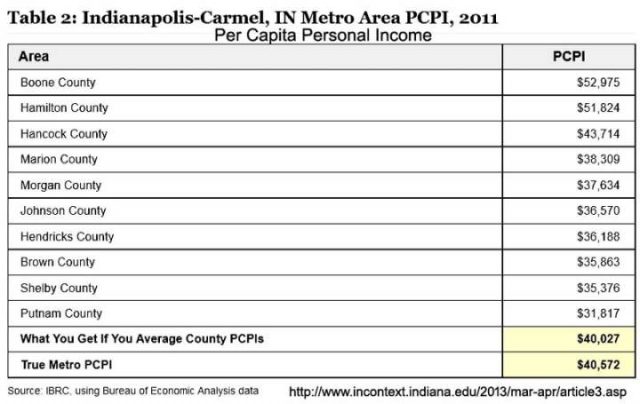
Informationen zum Pro-Kopf-Einkommen vom Indiana Business Research Center und hier deren Artikel mit dem Titel: „Was man mit Daten nicht machen darf: Durchschnittswerte zu mitteln.
Wie Sie sehen können, mittelt man die Durchschnittswerte der Landkreise, bekommt man ein Pro-Kopf Einkommen von $ 40,027, aber zuerst kumulieren und dann mitteln gibt die wahre (wahrere) Zahl von $ 40.527. Dieses Ergebnis hat einen Unterschied – einen Fehler – von 1,36%. Von Interesse für diejenigen in Indiana, nur die Top drei der Verdiener in den Landkreisen haben ein Pro-Kopf-Einkommen, dass höher ist als der Landesdurchschnitt nach jedem Rechenweg und acht Landkreise liegen unter dem Durchschnitt.
Das mag trivial für Sie sein, aber bedenken Sie, dass verschiedene Behauptungen von „auffallenden neuen medizinischen Entdeckungen“ und „dem heißesten Jahr überhaupt“ nur diese Art von Unterschieden in den Rechenwegen basieren, die im Bereich der einstelligen oder sogar Bruchteilen von Prozentpunkten liegen, oder ein Zehntel oder ein Hundertstel Grad.
Um das der Klimatologie zu vergleichen, so reichen die veröffentlichten Anomalien aus dem 30-jährigen Klima- Referenzzeitraum (1981-2011) für den Monat Juni 2017 von 0,38 ° C (ECMWF) bis 0,21 ° C (UAH), mit dem Tokyo Climate Center mit einem mittlerem Wert von 0,36 ° C. Der Bereich (0,17 ° C) beträgt fast 25% des gesamten Temperaturanstiegs für das letzte Jahrhundert. (0,71ºC). Selbst bei Betrachtung nur den beiden höchsten Werten: 0,38 ° C und 0,36 ° C, ergibt die Differenz von 0,02 ° C bereits 5% der Gesamtanomalie. [Kann man diesen Unterschied merken? – der Übersetzer]
Wie genau diese Mittelwerte im Ergebnis dargestellt werden, ist völlig unerheblich. Es kommt überhaupt nicht darauf an, ob man absolut Werte oder Anomalien schätzt – die Größe des induzierten Fehlers kann riesig sein
Ähnlich, aber nicht identisch, das ist Simpsons Paradox.
Simpsons Paradox, oder korrekter der Simpson-Yule-Effekt, ist ein Phänomen, das in Statistiken und Wahrscheinlichkeiten (und damit mit Mittelwerten) auftritt, oft in medizinischen Studien und verschiedenen Zweigen der Sozialwissenschaften zu sehen, in denen ein Ergebnis (z. Bsp. ein Trend- oder Auswirkungs-Unterschied) dargestellt wird, der beim Vergleich von Datengruppen verschwindet oder sich umkehrt, wenn die Gruppen (von Daten) kombiniert werden.
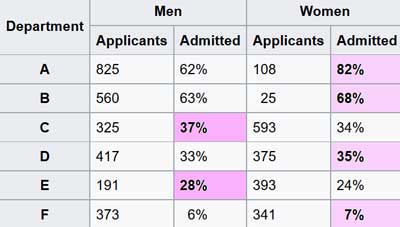
Einige Beispiele mit Simpsons Paradox sind berühmt. Eine mit Auswirkungen auf die heutigen heißen Themen behauptete Grundlage über die Anteile von Männer und Frauen bei den zum Studium an der UC Berkeley zugelassenen Bewerbern.
[Die 1868 gegründete University of California, Berkeley, gehört zu den renommiertesten Universitäten der Welt.]
Hier erklärt es einer der Autoren:
„Im Jahr 1973 wurde UC Berkeley für geschlechtsspezifische Regeln verklagt, weil ihre Zulassungszahlen zum Studium offensichtliche Nachteile gegen Frauen zeigen.
| UCB | Bewerber Applicants |
Zugelassen Admitted |
| Männer | 8442 | 44% |
| Frauen | 4321 | 35% |
Statistischer Beweis für die Anklage (Tabelle abgetippt)
Männer waren viel erfolgreicher bei der Zulassung zum Studium als Frauen und damit führte es Berkeley zu einer der ersten Universitäten, die für sexuelle Diskriminierung verklagt werden sollten. Die Klage scheiterte jedoch, als Statistiker jede Abteilung getrennt untersuchten. Die Fachbereiche haben voneinander unabhängige Zulassungssysteme, daher macht es Sinn, sie separat zu überprüfen – und wenn Sie das tun, dann sie scheinen eine Vorliebe für Frauen zu haben.“
In diesem Fall gaben die kombinierten (amalgamierten) Daten über alle Fachbereiche hinweg keine informative Sicht auf die Situation.
Natürlich, wie viele berühmte Beispiele, ist die UC Berkeley Geschichte eine wissenschaftliche Legende – die Zahlen und die mathematischen Phänomen sind wahr, aber es gab nie eine Klage wegen Benachteiligung von Geschlechtern. Die wahre Geschichte finden sie hier.
Ein weiteres berühmtes Beispiel für Simpsons Paradox wurde (mehr oder weniger korrekt) auf der langlaufenden TV-Serie Numb3rs vorgestellt. (Ich habe alle Episoden dieser Serie über die Jahre hinweg gesehen, einige öfter). Ich habe gehört, dass einige Leute Sportstatistiken mögen, also ist dieses etwas für Sie. Es „beinhaltet die durchschnittlichen Leistungswerte des Schlägers von Spielern im Profi-Baseball. Es ist möglich, dass ein Spieler in einer Reihe von Jahren einen höheren Durchschnitt der Abschlagwerte hat als ein anderer Spieler, obwohl er in all diesen Jahren nur einen niedrigeren Durchschnitt erreichte.“
Diese Tabelle zeigt das Paradox:

In jedem einzelnem Jahr erreichte David Justice einen etwas besseren Abschlag – Durchschnitt, aber wenn die drei Jahre kombiniert werden, hat Derek Jeter [auch tatsächlich ein Baseballspieler, Jg. 1974] die etwas bessere Statistik. Dies ist das Paradox von Simpson, die Ergebnisse werden umgekehrt, je nachdem ob mehrere Gruppen von Daten separat oder kumuliert betrachtet werden.
In der Klimatologie tendieren die verschiedenen Gruppen die Daten über längere Zeiträume zu betrachten, um die Nachteile der Mittelungsdurchschnitte zu vermeiden. Wie wir in den Kommentaren sehen, werden verschiedene Vertreter die verschiedenen Methoden gewichten und ihre Methoden verteidigen.
Eine Gruppe behauptet, dass sie überhaupt nicht mitteln – sie engagieren sich in „räumlicher Vorhersage“, die irgendwie magisch eine Vorhersage hervorbringt, die sie dann einfach als die globale durchschnittliche Oberflächentemperatur markieren (während sie gleichzeitig bestreiten, eine Mittelung durchgeführt zu haben). Sie fangen natürlich mit täglichen, monatlichen und jährlichen Durchschnitten an – aber das sind keine echten Mittelwerte…. mehr dazu später.
Ein anderer Experte mag behaupten, dass sie definitiv keine Durchschnittswerte der Temperaturen bilden – nur den Durchschnitt von Anomalien. Das heißt, sie berechnen erst die Anomalien und dann mitteln sie diese. Wenn sie energisch genug befragt werden, dann wird diese Fraktion zugeben, dass die Mittelung längst durchgeführt wurde, die lokalen Stationsdaten – die tägliche durchschnittliche „trockene“ [dry-bulb] -Temperatur – wird wiederholt gemittelt, um monatliche Mittelwerte zu erreichen, dann Jahresdurchschnitte. Manchmal werden mehrere Stationen gemittelt, um einen „Messzellen-Durchschnitt“ zu erreichen und dann werden diese jährlichen oder klimatischen Mittel von dem gegenwärtigen absoluten Temperaturdurchschnitt subtrahiert (monatlich oder jährlich, je nach Prozess), um einen Rest zu erhalten, der dann als sogenannte „Anomalie“ bezeichnet wird – oh, dann sind die Durchschnittswerte der Anomalien „gedurchschnittet“ (gemittelt).
Die Anomalien können oder können nicht, je nach Berechnungssystem, tatsächlich gleiche Flächen der Erdoberfläche darstellen. [Siehe den ersten Abschnitt für den Fehler bei der Mittelung von Durchschnittswerten, die nicht den gleichen Bruchteil des kumulierten Ganzen darstellen (~präsentieren)]. Diese Gruppe von Experten und fast alle anderen, verlassen sich auf „nicht echte Durchschnittswerte“ an der Wurzel ihrer Berechnungen.
Die Klimatologie hat ein Mittelungsproblem, aber das echte Problem ist nicht so sehr das, was oben diskutiert wurde. In der Klimatologie ist die tägliche Durchschnittstemperatur, die bei Berechnungen verwendet wird, kein Durchschnitt der Lufttemperaturen, die während der letzten 24-Stunden-Periode bei der Wetterstation erlebt oder aufgezeichnet wurden. Es ist das arithmetische Mittel der niedrigsten und höchsten aufgezeichneten Temperaturen (Lo und Hi, das Min Max) für den 24-Stunden-Zeitraum. Es ist zum Beispiel nicht der Durchschnitt aller stündlichen Temperaturaufzeichnungen, auch wenn sie aufgezeichnet und berichtet werden. Egal wie viele Messungen aufgezeichnet werden, der Tagesdurchschnitt wird berechnet, indem man den Lo und den Hi summiert und durch zwei teilt.
Die Temperaturen wurden als hoch und niedrig (Min-Max) für 150 Jahre oder mehr aufgezeichnet. Das ist genau so, wie es gemacht wurde und um konsequent zu bleiben, so macht man es auch heute noch.
Ein Daten-Download von Temperaturaufzeichnungen für die Wetterstation WBAN: 64756, Millbrook, NY, für Dezember 2015 bis Februar 2016 enthält alle fünf Minuten eine Temperaturablesung. Der Datensatz enthält Werte für „DAILYMaximumDryBulbTemp“ und „DAILYMinimumDryBulbTemp“, gefolgt von „DAILYAverageDryBulbTemp“, alles in Grad Fahrenheit. Die „DAILYAverageDryBulbTemp“ durchschnittliche trockene Temperatur ist das arithmetische Mittel der beiden vorhergehenden Werte (Max und Min). Dieser letzte Wert wird in der Klimatologie als die tägliche durchschnittliche Temperatur verwendet. Für einen typischen Dezembertag sehen die aufgezeichneten Werte so aus:
Täglich Max 43 F – Täglich Min 34 F – Täglicher Durchschnitt 38F (das arithmetische Mittel ist eigentlich 38,5, aber der Algorithmus rundet x,5 ab auf x)
Allerdings ist der Tagesdurchschnitt aller aufgezeichneten Temperaturen: 37.3 F… Die Differenzen für diesen einen Tag:
Unterschied zwischen dem berichteten Tagesdurchschnitt von Hi-Lo und dem tatsächlichen Durchschnitt der aufgezeichneten Hi-Lo-Zahlen ist = 0,5 ° F aufgrund des Rundungsalgorithmus.
Unterschied zwischen dem angegebenen Tagesdurchschnitt und dem korrekteren Tagesdurchschnitt unter Verwendung aller aufgezeichneten Temperaturen = 0,667 ° F
Andere Tage im Januar und Februar zeigen einen Differenzbereich zwischen dem gemeldeten täglichen Durchschnitt und dem Durchschnitt aller aufgezeichneten Temperaturen von 0,1 ° F bis 1,25 ° F bis zu einem hohen Wert von 3,17 ° F am 5. Januar 2016.
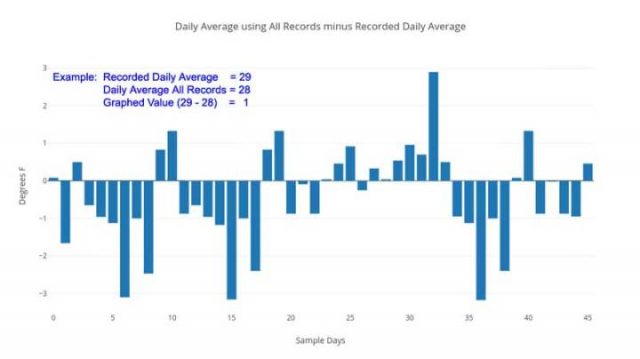
Täglicher Durchschnittswert aller Aufzeichnungen, korrekte Rechnung minus des aufgezeichneten Durchschnitts.
Dies ist kein wissenschaftliches Sampling – aber es ist eine schnelle Fallstudie, die zeigt, dass die Zahlen von Anfang an gemittelt werden – als tägliche Durchschnittstemperaturen, die offiziell an den Oberflächenstationen aufgezeichnet wurden. Die unmodifizierten Grunddaten selbst, werden in keinem Fall für die Genauigkeit oder Präzision überhaupt berechnet [zur Berechnung herangezogen] – aber eher werden berechnet „wie wir das schon immer getan haben“ – der Mittelwert zwischen den höchsten und niedrigsten Temperaturen in einer 24-Stunden-Periode – das gibt uns nicht einmal, was wir normalerweise als „Durchschnitt“ erwarten würden für die Temperatur an diesem Tag „- aber irgendeinen anderen Wert – ein einfaches Mittel zwischen dem Daily Lo und dem Daily Hi, das, wie die obige Grafik offenbart, ganz anders zu sein scheint. Der durchschnittliche Abstand von Null [Abweichung, d.h. wie es korrekt wäre] für die zweimonatige Probe beträgt 1,3 ° F. Der Durchschnitt aller Unterschiede, unter Beachtung des Vorzeichens beträgt 0,39 ° F [also in Richtung wärmer].
Die Größe dieser täglichen Unterschiede? Bis zu oder [sogar] größer als die gemeinhin gemeldeten klimatischen jährlichen globalen Temperaturanomalien. Es spielt keine Rolle, ob die Unterschiede nach oben oder unten zählen – es kommt darauf an, dass sie implizieren, dass die Zahlen, die verwendet werden, um politische Entscheidungen zu beeinflussen, nicht genau berechnete, grundlegende täglichen Temperaturen von einzelnen Wetterstationen sind. Ungenaue Daten erzeugen niemals genaue Ergebnisse. Persönlich glaube ich nicht, dass dieses Problem bei der Verwendung von „nur Anomalien“ verschwindet (was einige Kommentatoren behaupten) – die grundlegenden Daten der ersten Werteebene sind falsch, unpräzise, ungenau berechnet.
Aber, aber, aber … Ich weiß, ich kann die Maulerei bereits jetzt hören. Der übliche Chor von:
Die beiden ersten Argumente sind fadenscheinig.
Das letzte will ich ansprechen. Die Antwort liegt in dem „Warum“ der oben beschriebenen Unterschiede. Der Grund für den Unterschied (außer der einfachen Auf- und Abwärtsbewegung von Bruchteilen in ganzem Grad) ist, dass die Lufttemperatur an einer beliebigen Wetterstation nicht normal verteilt wird … das heißt, von Minute zu Minute oder Stunde zu Stunde, keiner würde eine „normal Verteilung“ sehen, die sich so darstellt:
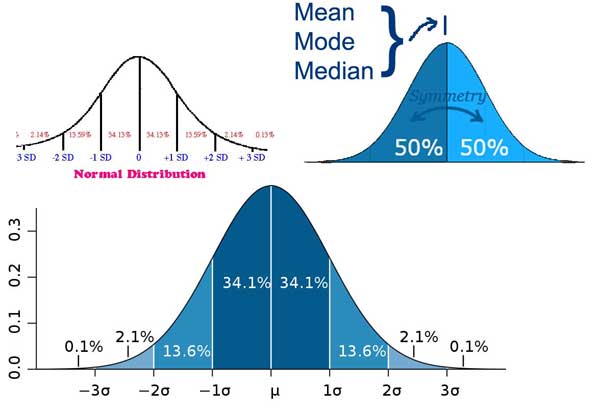
Normal-oder-Standard-Verteilung
Wenn die Lufttemperatur normalerweise so über den Tag verteilt wäre, dann wäre die aktuell verwendete tägliche durchschnittliche trockene Temperatur – das arithmetische Mittel zwischen dem Hi und Lo – korrekt und würde sich nicht vom täglichen Durchschnitt aller aufgezeichneten Temperaturen für den Tag unterscheiden.
Aber echte Oberflächentemperaturen der Luft sehen viel mehr aus, wie diese drei Tage von Januar und Februar 2016 in Millbrook, NY:
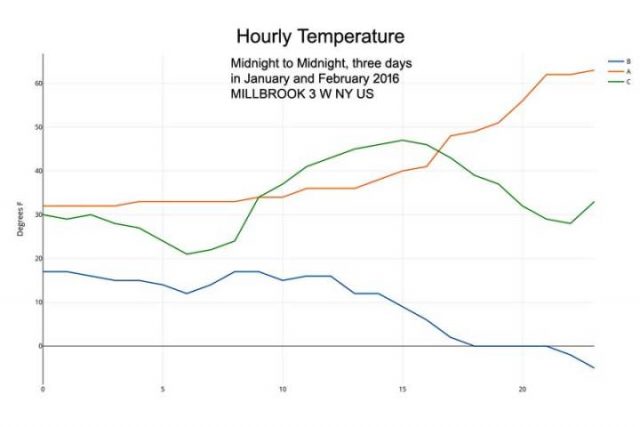
Reale stündliche Temperaturen
Die Lufttemperatur an einer Wetterstation startet nicht am Lo Wert – um gleichmäßig und stetig zum Hi aufzusteigen und sich dann gleichmäßig zum nächsten Lo zurück zu schleichen. Das ist ein Mythos – jeder der sich draußen aufhält (Jäger, Seemann, Camper, Forscher, sogar Jogger) kennt diese Tatsache. Doch in der Klimatologie werden die tägliche Durchschnittstemperatur – und konsequent alle nachfolgenden wöchentlichen, monatlichen, jährlichen Durchschnitte – auf der Grundlage dieser falschen Idee berechnet.
Zuerst nutzten die Wetterstationen Min-Max-Aufnahmethermometer und wurden oft nur einmal pro Tag überprüft und die Aufnahme-Tabs zu diesem Zeitpunkt zurückgesetzt – und nun so weitergeführt aus Respekt für Konvention und Konsistenz.
Wir können nicht zurückkehren und die Fakten rückgängig machen – aber wir müssen erkennen, dass die täglichen Mittelwerte aus diesen Min-Max / Hi-Lo-Messwerten nicht die tatsächliche tägliche Durchschnittstemperatur darstellen – weder in Genauigkeit noch in Präzision. Dieses beharren auf Konsistenz bedeutet, dass die Fehlerbereiche, die in dem obigen Beispiel dargestellt sind, alle globalen durchschnittlichen Oberflächentemperaturberechnungen beeinflussen, die Stationsdaten als Quelle verwenden.
Anmerkung: Das hier verwendete Beispiel ist von Wintertagen in einem gemäßigten Klima. Die Situation ist repräsentativ, aber nicht unbedingt quantitativ – sowohl die Werte als auch die Größen der Effekte werden für verschiedene Klimazonen [… Gegenden], verschiedene Stationen, verschiedene Jahreszeiten unterschiedlich sein. Der Effekt kann durch statistische Manipulation oder durch Reduzierung der Stationsdaten zu Anomalien nicht vermieden werden.
Alle Anomalien, die durch Subtrahieren von klimatischen Durchschnittswerten von aktuellen Temperaturen abgeleitet werden, werden uns nicht mitteilen, ob die durchschnittliche absolute Temperatur an einer Station steigt oder fällt (oder um wie viel). Es wird uns nur sagen, dass der Mittelwert zwischen den täglichen Hochtemperaturen steigt oder fällt – was etwas ganz anders ist. Tage mit sehr niedrigen Tiefs für eine Stunde oder zwei am frühen Morgen gefolgt von hohen Temperaturen für die meiste Zeit des restlichen Tages haben die gleichen Max-Min Mittelwerte wie Tage mit sehr niedrigen Tiefs für 12 Stunden und eine kurze heiße Spitze am Nachmittag. Diese beiden Arten von Tagen, haben nicht die gleiche tatsächliche durchschnittliche Temperatur. Anomalien können den Unterschied nicht erhellen. Ein Klimawandel von einem zum anderen wird in Anomalien nicht auftauchen. Weder noch würde die Umwelt von einer solchen Verschiebung stark betroffen sein.
Es gibt einige die in Frage stellen, dass es tatsächliche eine globale durchschnittliche Oberflächentemperatur gibt. (Siehe „Gibt es eine globale Temperatur?“)
Auf der anderen Seite, formulierte Steven Mosher in seinem Kommentar kürzlich so treffend:
Sind abgeleitete Temperaturen bedeutungslos?
Ich denke, dass es schlecht ist, wenn Alarmisten versuchen, die kleine Eiszeit und die Mittelalterliche Warmzeit zu löschen … WUWT wird die ganze Geschichte leugnen wollen. Die globale Temperatur ist vorhanden. Es hat eine genaue physikalische Bedeutung. Es ist diese Bedeutung, die uns erlaubt zu sagen … Die kleine Eiszeit war kühler als heute … es ist die Bedeutung, die es uns erlaubt, zu sagen, dass die die Tagseite des Planeten wärmer ist als die Nachtseite … die gleiche Bedeutung, die uns erlaubt zu sagen, dass Pluto kühler ist als die Erde und dass Merkur wärmer ist.
Was ein solcher globaler Mittelwert, basierend auf einen fragwürdigen abgeleiteten „Tagesdurchschnitt“, uns nicht sagen kann, ist oder war es in diesem Jahr ein Bruchteil eines Grades wärmer oder kühler?
Der Berechnungsfehler – der Messfehler – der am häufigsten verwendeten Station der täglichen durchschnittlichen Durchschnittstemperatur ist in der Größe gleich (oder nahezu gleich groß) wie die langfristige globale Temperaturänderung. Die historische Temperaturaufzeichnung kann nicht für diesen Fehler korrigiert werden. Moderne digitale Aufzeichnungen würde eine Neuberechnung der Tagesmittelwerte von Grund auf neu erfordern. Selbst dann würden die beiden Datensätze quantitativ nicht vergleichbar sein – möglicherweise nicht einmal qualitativ.
Es ist sehr wichtig, wie und was man mittelt. Es macht was aus, den ganzen Weg nach oben und unten durch das prächtige mathematische Wunderland, was die Computerprogramme darstellen, die diese grundlegenden digitalen Aufzeichnungen von Tausenden von Wetterstationen auf der ganzen Welt lesen und sie zu einer einzigen Zahl verwandeln.
Es macht vor allem dann etwas aus, wenn diese einzelne Zahl dann später als Argument verwendet wird, um die breite Öffentlichkeit zu treffen und unsere politischen Führer zu bestimmten gewünschten politischen Lösungen zu bringen (~ zu zwingen), die große – und viele glauben negative – Auswirkungen auf die Gesellschaft haben werden.
Es reicht nicht aus, den Durchschnitt eines Datensatzes korrekt mathematisch zu berechnen.
Es reicht nicht aus, die Methoden zu verteidigen, die Ihr Team verwendet, um die [oft-mehr-missbrauchten-als-nicht] globalen Mittelwerte von Datensätzen zu berechnen.
Auch wenn diese Mittelwerte von homogenen Daten und Objekten sind und physisch und logisch korrekt sind, ein Mittelwert ergibt eine einzelne Zahl und kann nur fälschlicherweise als summarische oder gerechte Darstellung des ganzen Satzes, der ganzen Information angenommen werden.
Durchschnittswerte, in jedem und allen Fällen, geben natürlicherweise nur einen sehr eingeschränkten Blick auf die Informationen in einem Datensatz – und wenn sie als Repräsentation des Ganzen akzeptiert werden, wird sie als Mittel der Verschleierung fungieren, die den Großteil verdecken und die Information verbergen. Daher, anstatt uns zu einem besseren Verständnis zu führen, können sie unser Verständnis des zu untersuchenden Themas reduzieren.
In der Klimatologie wurden und werden tägliche Durchschnittstemperaturen ungenau und unpräzise aus den täglichen minimalen und maximalen Temperaturen berechnet, die damit Zweifel an den veröffentlichten globalen durchschnittlichen Oberflächentemperaturen hervorrufen.
Durchschnitte sind gute Werkzeuge, aber wie Hämmer oder Sägen müssen sie korrekt verwendet werden, um wertvolle und nützliche Ergebnisse zu produzieren. Durch den Missbrauch von Durchschnittswerten verringert sich das Verständnis des Themas eher, als das es die Realität abbildet.
UPDATE:
Diejenigen, die mehr Informationen bekommen wollen, über die Unterschiede zwischen Tmean (das Mittel zwischen Täglichem Min und Max) und Taverage (das arithmetische Mittel aller aufgezeichneten 24 stündlichen Temperaturen – einige verwenden T24 dafür) – sowohl quantitativ als auch in jährlichen Trends beziehen sich beide auf die Spatiotemporal Divergence of the Warming Hiatus over Land Based on Different Definitions of Mean Temperature von Chunlüe Zhou & Kaicun Wang [Nature Scientific Reports | 6:31789 | DOI: 10.1038/srep31789].[~Räumliche und zeitliche Abweichungen der Erwärmungspause über Land auf der Grundlage verschiedener Definitionen der mittleren Temperatur] von Chunlüe Zhou & Kaicun Wang [Nature Scientific Reports | 6: 31789 | DOI: 10.1038 / srep31789]. Im Gegensatz zu Behauptungen in den Kommentaren, dass Trends dieser unterschiedlich definierten „durchschnittlichen“ Temperaturen gleich sind, zeigen Zhou und Wang diese Figur und Kation: (h / t David Fair)
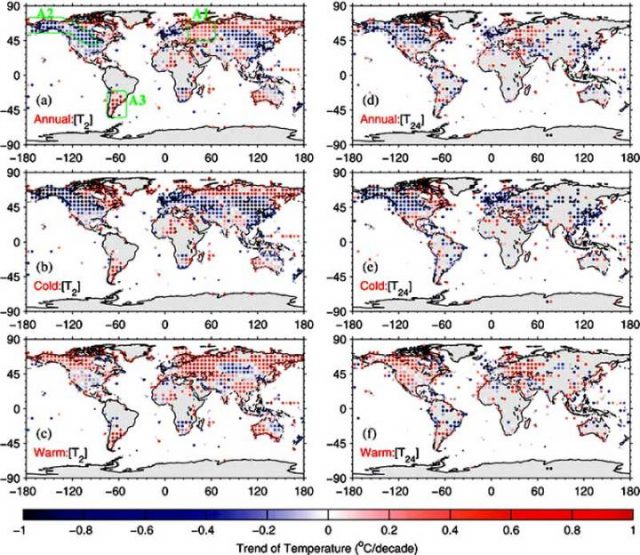
Abbildung 4. Die (a, d) jährliche, (b, e) Kälte und (c, f) warme saisonale Temperaturtrends (Einheit: ° C / Jahrzehnt) aus dem Global Historical Climatology Network-Daily Version 3.2 (GHCN-D , [T2]) und die „Integrated Surface Database-Hourly“ (ISD-H, [T24]) sind für 1998-2013 gezeigt. Die GHCN-D ist eine integrierte Datenbank der täglichen Klimazusammenfassungen von Land-Oberflächenstationen auf der ganzen Welt, die Tmax und Tmin Werte von rund 10.400 Stationen von 1998 bis 2013 zur Verfügung stellt. Die ISD-H besteht aus globalen stündlichen und synoptischen Beobachtungen bei etwa 3400 Stationen aus über 100 Originaldatenquellen. Die Regionen A1, A2 und A3 (innerhalb der grünen Regionen, die in der oberen linken Teilfigur gezeigt sind) werden in dieser Studie ausgewählt.
[Klicken Sie hier für ein Bild in voller Größe] in Nature
Erschienen auf WUWT am 24.07.2017
Übersetzt durch Andreas Demmig
https://wattsupwiththat.com/2017/07/24/the-laws-of-averages-part-3-the-average-average/

Zugegeben, den größten Teil dieser schönen Schlagzeile habe ich von Henryk M. Broder auf ACHGUT geklaut. Und der entnahm sie vermutlich einem uralten, etwas delikatem Witz[1]. Doch uns beiden fiel wohl gleichzeitig einige Berichte über Umfragen auf, die zum Nachdenken Anlass geben.
Bei Broder liest sich das so:
Von Henryk.M. Broder.
Eine Emnid-Umfrage im Auftrag der BamS ergab, dass nur 29% der Bundesbürger das Thema „Zuwanderung“ als „äußerst oder sehr wichtig“ für ihre Wahlentscheidung halten. Eine Woche später ergab eine Umfrage der Gesellschaft für Konsumforschung, dass kein anderes Thema die Deutschen so sehr umtreibt „wie die Zuwanderung und Integration von Ausländern“. Seltsam, nicht wahr? Der Unterschied könnte mit der Methodik der Umfragen zu tun haben. Während Emnid einer wie immer „repräsentativen Auswahl“ von Bügern die Frage stellte „Wie wichtig sind Ihnen für Ihre Stimmabgabe bei der Bundestagswahl die folgenden Aufgabenbereiche?“ und die Bereiche auflistete, waren bei der GfK-Umfrage keine Antworten vorgegeben. Die Teilnehmer der Umfrage konnten „frei antworten, in Worte fassen, was sie am meisten besorgt“. – So einfach kann eine Erklärung für das Unerklärliche sein. Und wie einfach es ist, das Ergebnis einer Umfrage durch die Art der Fragestellung zu manipulieren. / Link zum Fundstück
Bei mir war die Ausgangslage etwas anders. Es ging – natürlich- um die vermeintliche Klimaangst der Deutschen. Da behauptete z.B. die Berliner Morgenpost – eine Zeitung der Funke-Mediengruppe- dass, …die Mehrheit der Deutschen denkt laut einer jüngsten Umfrage des Kantar Emnid Instituts, dass Klimawandel das dringendste Problem der Gegenwart ist.“
Diese Erkenntnis des jetzt Kantar Emnid Institutes wurde recht breit auch in anderen Medien und nicht nur von Funke verbreitet.
Im Einzelnen findet man im Beitrag der Morgenpost:
Danach sagen 71 Prozent der Befragten, die Veränderung des Weltklimas bereite ihnen persönlich besonders große Sorgen. 65 Prozent führen neue Kriege als beherrschende Furcht an. Bei 63 Prozent sind es Terroranschläge, 62 Prozent nennen Kriminalität, und 59 Prozent ängstigen sich vor Altersarmut. Mit einigem Abstand folgt die Zuwanderung von Flüchtlingen (45 Prozent). Arbeitslosigkeit ist mit 33 Prozent die geringste der genannten Sorgen.
Weil mir diese Reihenfolge angesichts der täglichen Berichte in allen Medien komisch vorkam, nicht nur in Bezug auf das Klima, rief ich bei Kantar Emnid an, und bat um die Nennung der Fragestellung, die dieser Umfrage zugrunde lägen.
Man beschied mich abschlägig, da diese Eigentum der Funke Mediengruppe seien, und sie nicht darüber verfügen dürften. Und auch aus mehreren Artikeln anderer Medien konnte man nirgends entnehmen, wie und was gefragt wurde. Da gab ich auf.
Aber fast zeitgleich wurde eine Studie des PEW Centers mit 1000 Befragten in Deutschland (z.B. hier) veröffentlicht, die transparenter ist, und bei welcher der Klimawandel nur auf Pos. 3 der Besorgnisse landete. Aber immerhin noch von 63 % der Befragten angegeben wurde.
Und nun die Umfrage der Gesellschaft für Konsumforschung (GFK)!
Stattdessen steht die Furcht vor Zuwanderung/Migration deren Belastung und Kosten ja gerade erst beginnen sich in unserem Alltag zu verfestigen, an prominent erster Stelle.
Warum?
Weil die Befragten – oder soll man besser sagen- die beeinflussten Probanden diesmal- „frei antworten konnte, in Worte fassen, was sie am meisten besorgt“.
Die zu beantwortende Frage lautet: „Was sind Ihrer Meinung nach die dringendsten Aufgaben, die heute in Deutschland zu lösen sind?“
Und da liegt das Thema Zuwanderung/Migration mit ca. 63 %, also Riesenabstand, weit, weit vorn.
Die einen sagen eben so, die anderen so.
Wobei man zu Annahme kommen könnte, dass die einen die Meinungsmacher – genannt Umfrage-Institute- sind, während die anderen, die Leute von der Straße sind, also wir!
Und es drängt sich die Frage auf: Ist die Beeinflussung der Befragten nicht auch bei anderen Umfragen gängige Praxis?
Seufz! Fragen über Fragen.
Die weise Aussage eines Staatmannes „glaube keiner Statistik die Du nicht selber gefälscht hast“ bestätigt sich eben immer wieder.
[1] Der Witz geht so: Fragt ein Freund den anderen: „Na, wie ist denn Deine Frau so im Bett?“ Darauf der Andere: „Die einen sagen so, die andern so!“

Durchschnittliches
Sowohl das Wort als auch das Konzept „Durchschnitt“ sind in der breiten Öffentlichkeit sehr viel Verwirrung und Missverständnis unterworfen und sowohl als Wort als auch im Kontext ist eine überwältigende Menge an „lockerem Gebrauch“ auch in wissenschaftlichen Kreisen zu finden, ohne die Peer-Reviewed-Artikel in Zeitschriften und wissenschaftlichen Pressemitteilungen auszuschließen.
In Teil 1 dieser Serie [Eike, übersetzt] lasen Sie meine Auffrischung über die Begriffsinhalte von Durchschnitten, Mittelwerten und Beispiele dazu. Wenn Ihnen diese Grundlagen nun geläufig sind, dann können wir mit den weiteren Gedankengängen weitermachen.
Wer es vorher oder nochmal lesen möchte, hier ist der Link zum Original [Part 1 of this series]
Ein Strahl der Finsternis in das Licht [Übersetzung des Originaltitels]
oder: Informieren um zu Verschleiern
Der Zweck, zu einem Datensatz verschiedene Ansichten darzustellen – oder über jede Sammlung von Informationen oder Messungen, über eine Klasse von Dingen oder ein physikalisches Phänomen – ist es, dass wir diese Informationen aus verschiedenen intellektuellen und wissenschaftlichen Winkeln sehen können – um uns einen besseren Einblick in das Thema unserer Studien zu geben, was hoffentlich zu einem besseren Verständnis führt.
Moderne statistische Programme erlauben es sogar Gymnasiasten, anspruchsvolle statistische Tests von Datensätzen durchzuführen und die Daten auf unzählige Weise zu manipulieren [bzw. zu sortieren] und zu betrachten. In einem breiten allgemeinen Sinne, ermöglicht die Verfügbarkeit dieser Softwarepakete nun Studenten und Forschern, (oft unbegründete) Behauptungen für ihre Daten zu machen, indem sie statistische Methoden verwenden, um zu numerischen Ergebnissen zu gelangen – alles ohne Verständnis weder der Methoden noch der wahren Bedeutung oder Aussagekraft der Ergebnisse. Ich habe das erfahren, indem ich High School Science Fairs beurteile [zu vergleichen mit „Jugend forscht“] und später die in vielen Peer-Review-Journalen gemachten Behauptungen gelesen habe. Eine der derzeit heiß diskutierten Kontroversen ist die Prävalenz [allgemeine Geltung] der Verwendung von „P-Werten“ [probability value ~ Wahrscheinlichkeitswert], um zu beweisen, dass [auch] triviale Ergebnisse irgendwie signifikant sind, weil „das die Aussage ist, wenn die P-Werte geringer als 0,05 sind“. Die High School Science Fair Studenten bezogen auch ANOVA Testergebnisse über ihre Daten mit ein –jedoch konnte keiner von ihnen erklären, was ANOVA ist oder wie es auf ihre Experimente angewendet wurde.
[Als Varianzanalyse (ANOVA von englisch analysis of variance) bezeichnet man eine große Gruppe datenanalytischer und strukturprüfender statistischer Verfahren, die zahlreiche unterschiedliche Anwendungen zulassen; Quelle Wikipedia]
Moderne Grafik-Tools ermöglichen alle Arten von grafischen Methoden um Zahlen und ihre Beziehungen anzuzeigen. Das US Census Bureau [statistisches Amt] verfügt über einen große Anzahl von Visualisierungen und Graphikwerkzeugen. Ein Online-kommerzieller Service, Plotly, kann in wenigen Sekunden eine sehr beeindruckende Reihe von Visualisierungen Ihrer Daten erstellen. Sie bieten einen kostenlosen Service an, dessen Niveau mehr als ausreichend für fast alle meine Verwendungen war (und eine wirklich unglaubliche Sammlung von Möglichkeiten für Unternehmen und Profis mit einer Gebühr von etwa einem Dollar pro Tag). RAWGraphs hat einen ähnlichen kostenlosen Service.
Es werden komplexe Computerprogramme verwendet, um Metriken wie die globalen Durchschnittlichen Land– und Meerestemperaturen oder die globale mittlere Höhe des Meeresspiegels zu erstellen. Ihre Schöpfern und Promotoren glauben daran, das damit tatsächlich ein einziger aussagekräftiger Wert produziert werden kann, der eine durchschnittliche Genauigkeit bis zu einem Hundertstel oder Tausendstel oder eines Millimeters erreicht. Oder, wenn schon nicht aktuelle quantitativ genaue Werte, so werden zumindest genaue Anomalien oder gültige Trends berechnet. Die Meinungen zu diesen Werten variieren sehr stark, betreffend der Gültigkeit, der Fehlerfreiheit und der Genauigkeit dieser globalen Durchschnittswerte.
Die Mittelwerte sind nur eine von unterschiedlichsten Möglichkeiten, die Werte in einem Datensatz zu betrachten. Wie ich in den Grundlagen für den „Durchschnitt“ erklärt habe, gibt es drei primäre Arten von Mittelwerten – Mittel, Median und Mode – sowie weitere exotische Typen.
In Teil 1 dieser Reihe erklärte ich die Fallstricke von Mittelwerten von heterogenen, nicht miteinander zu vergleichenden Objekten oder Daten über Gegenstände. Solche Versuche enden mit „Obstsalat“, ein Durchschnitt aus Äpfeln und Orangen ergibt unlogische oder unwissenschaftliche Ergebnisse, mit Bedeutungen, die illusorisch, imaginär oder von so geringer Aussage und damit nicht sehr nützlich sind. Solche Mittelungen werden oft von ihren Schöpfern mit Bedeutung – Sinn – erfüllt, die sie nicht haben.
Da der Zweck, Daten auf unterschiedliche Weise zu betrachten – wie das Betrachten eines Durchschnitts, ein Mittelwert oder ein Modus des numerischen Datensatzes – zu einem besseren Verständnis führen soll, ist es wichtig zu verstehen, was tatsächlich passiert, wenn numerische Ergebnisse gemittelt werden und in welcher Weise sie zu einem besseren Verständnis führen und in welcher Weise sie aber auch zu einem reduzierten Verständnis führen können.
Ein einfaches Beispiel:
Betrachten wir die Größe der Jungs in Frau Larsens hypothetischer 6. Klasse an einer Jungenschule. Wir wollen ihre Größe kennenlernen, um eine horizontale Klimmzugstange zwischen zwei starken, aufrechten Balken platzieren, damit sie trainieren können (oder als leichte konstruktive Strafe – „Jonny – Zehn Klimmzüge bitte!“). Die Jungs sollten in der Lage sein, sie leicht zu erreichen, indem man ein bisschen hochspringt, so dass beim Hängen an den Händen ihre Füße nicht den Boden berühren.
Die ärztliche Station liefert uns die Größen der Jungs, die gemittelt werden, und wir erhalten das arithmetische Mittel von 65 Zoll [ = 165 cm; für den weiteren Vergleich lasse ich Zoll (= Inch) stehen].
Mit diesen Durchschnittsgrößen rechnen wir weiter, um die benötigte Stangenhöhe in Zoll zu ermitteln:
Größe / 2.3 = Armlänge (Schulter zu den Fingerspitzen)
= 65 / 2.3 = 28 (ungefähre Armlänge)
= 65 + 28 = 93 Zoll = 7,75 Fuß oder 236 cm
Unsere berechnete Höhe der Stange passt gut in ein Klassenzimmer mit 8,5 Fuß Decken, also sind wir gut. Oder sind wir gut? Haben wir genügend Informationen aus unserer Berechnung der Mittleren Höhe?
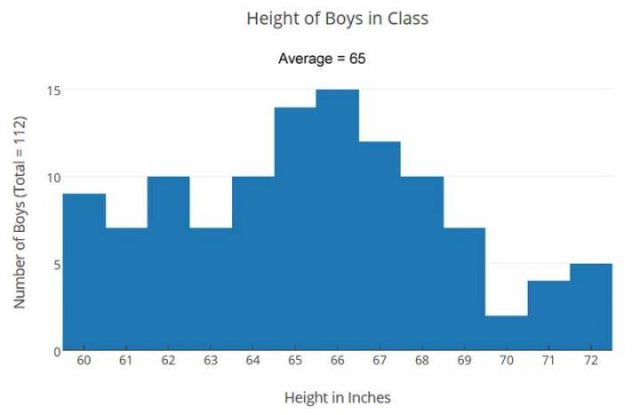
Lassen Sie es uns überprüfen, indem wir ein Balkendiagramm aller Größen aller Jungs betrachten:
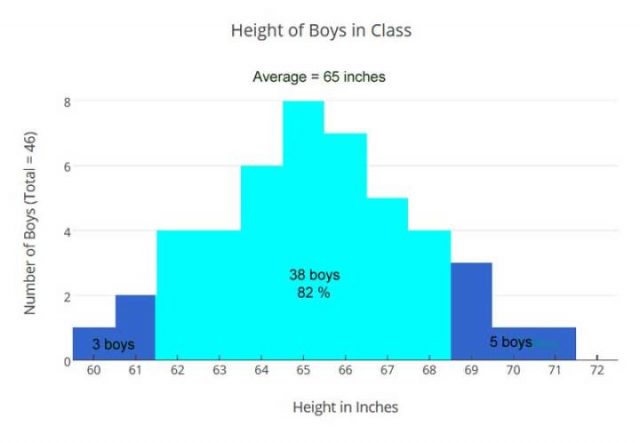
Diese Visualisierung, gibt uns eine andere Sicht als unser berechneter Durchschnitt – um die vorhandenen Informationen zu betrachten – um die Daten der Größen der Jungen in der Klasse auszuwerten. Mit der Erkenntnis, dass die Jungen von nur fünf Fuß groß (60 Zoll) bis hin zu fast 6 Fuß (71 Zoll) groß sind, werden wir nicht in der Lage sein, eine Stangenhöhe festzulegen, die ideal für alle ist. Allerdings sehen wir jetzt, dass 82% der Jungs innerhalb der Mittelhöhe von 3 Inch liegen und unsere berechnete Stangenhöhe wird gut für sie sein. Die 3 kürzesten Jungs könnten einen kleinen Tritt brauchen, um die Stange zu erreichen, und die 5 längsten Jungs können ihre Knie ein bisschen beugen, um Klimmzüge zu machen. Also können wir es so machen.
Aber als wir den gleichen Ansatz in Mr. Jones ‚Klasse versuchten, hatten wir ein Problem.
Es gibt 66 Jungen in dieser Klasse und ihre durchschnittliche Größe (Mittelwert) ist auch 65 Zoll, aber die Größen sind anders verteilt:
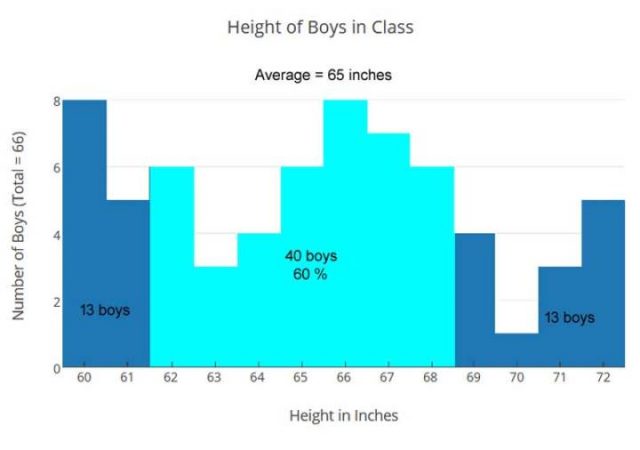
Jungens, die zweite Klasse
Herr Jones Klasse hat eine andere Mischung, die zu einer ungleichen Verteilung führt, viel weniger um den Mittelwert zentriert. Mit dem gleichen Durchschnitt: +/- 3 Zoll (hellblau), der in unserem vorherigen Beispiel verwendet wurden, erfassen wir nur 60% der Jungs anstatt 82%. In Mr. Jones Klasse, würden 26 von 66 Jungs die horizontale Reckstange bei 93 Zoll nicht bequem finden. Für diese Klasse war die Lösung eine variable Höhenleiste mit zwei Einstellungen: eine für die Jungen 60-65 Zoll groß (32 Jungen), eine für die Jungen 66-72 Zoll groß (34 Jungen).
Für die Klasse von Herrn Jones war die durchschnittliche Größe, die mittlere Größe, nicht dazu geeignet, um uns ein besseres Verständnis die Informationen über die Höhe der Jungen zu beleuchten, zu ermöglichen. Wir brauchten einen genaueren Blick auf die Informationen, um unseren Weg durch die bessere Lösung zu sehen. Die variable Höhenleiste funktioniert auch für Mrs. Larsens Klasse gut, mit der unteren Einstellung für 25 Jungen und die höhere Einstellung gut für 21 Jungen.
Die Kombination der Daten aus beiden Klassen gibt uns diese Tabelle:
Dieses kleine Beispiel soll veranschaulichen, dass Mittelwerte, wie unsere mittlere Höhe, unter Umständen von Nutzen sind, aber nicht in allen Fällen.
In der Klasse von Herrn Jones war die größere Anzahl kleinerer Jungen verdeckt, versteckt, gemittelt, man kann sich auf die mittlere Höhe verlassen, um die besten Lösungen für die horizontale Klimmstange zu bekommen.
Es ist erwähnenswert, dass in Frau Larsens Klasse, die Jungens eine Verteilung der Größen haben – siehe erstes Diagramm oben, die der sogenannten Normalverteilung ähnlich ist, ein Balkendiagramm wie folgend gezeigt:
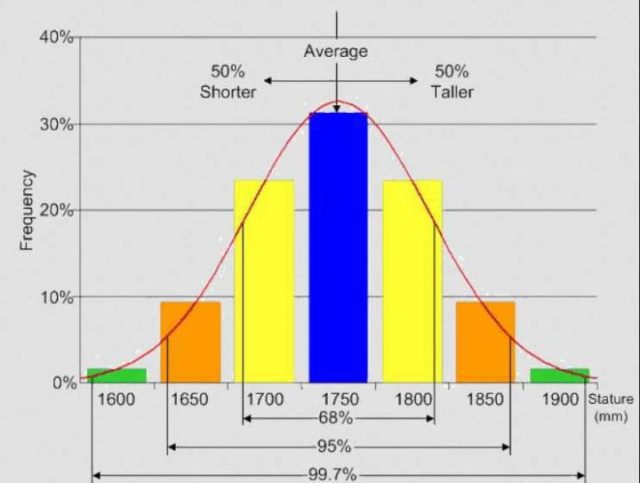
Normalverteilung
Die meisten Werte ergeben einen Gipfel in der Mitte und fallen mehr oder weniger gleichmäßig davor und dahinter ab. Durchschnitte sind gute Schätzungen für Datensätze, die so aussehen. Dabei muss man dann darauf achten, auch die Bereiche auf beiden Seiten des Mittels zu verwenden.
Mittel sind nicht so gut für Datensätze wie es Herr Jones‘ Klasse zeigt oder für die Kombination der beiden Klassen. Beachten Sie, dass das Arithmetische Mittel genau das gleiche für alle drei Datensätze der Größe der Jungen ist – die beiden Klassen und die kombinierten – aber die Verteilungen sind ganz anders und führen zu unterschiedlichen Schlussfolgerungen.
Das durchschnittliche Haushaltseinkommen in USA
Eine häufige angewandte Messgröße für das wirtschaftliche Wohlbefinden in den Vereinigten Staaten ist die jährliche Ermittlung des durchschnittlichen Haushaltseinkommens durch das statistische Amt [US Census Bureau].
Erstens, dass es als MEDIAN gegeben wird – was bedeutet, dass es eine gleich große Anzahl von Familien mit einem größeren Einkommen sowie auch Familien unter diesem Einkommensniveau geben sollte. Diese Grafik hier, von der jeweils regierenden Partei veröffentlicht – unabhängig davon, ob es die Demokraten oder die Republikaner sind – wird vom Oval Office (US-Präsident) und den beiden Häusern des Kongresses gerne als Argument [für ihre gute Arbeit] genutzt:
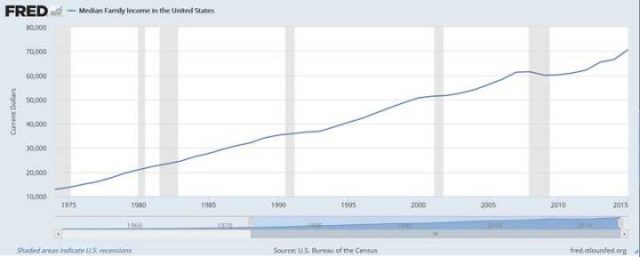
Das ist die gute Nachricht!
Grafik: Das mediane Familien Einkommen zeigt über die Jahre einem schönen stetigen Aufstieg und wir singen alle zusammen mit dem Beatles: “I’ve got to admit it’s getting better, A little better all the time…” [Sgt. Pepper’s Lonely Hearts Club Band]
Die nächste Grafik zeigt die nicht so gute Nachricht:
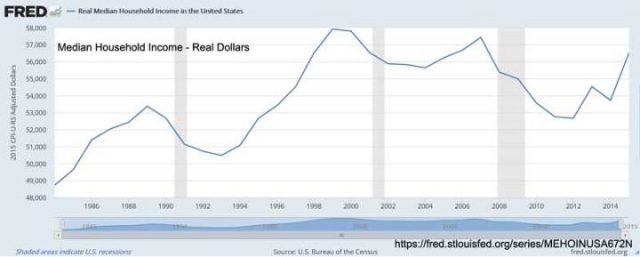
Die Zeitachse ist auf 1985 bis 2015 verkürzt, aber wir sehen, dass die Familien seit etwa 1998 nicht viel, wenn überhaupt, an realer Kaufkraft gewonnen haben, bereinigt um die Inflation.
Und dann gibt es die Grafik der Wirklichkeit:
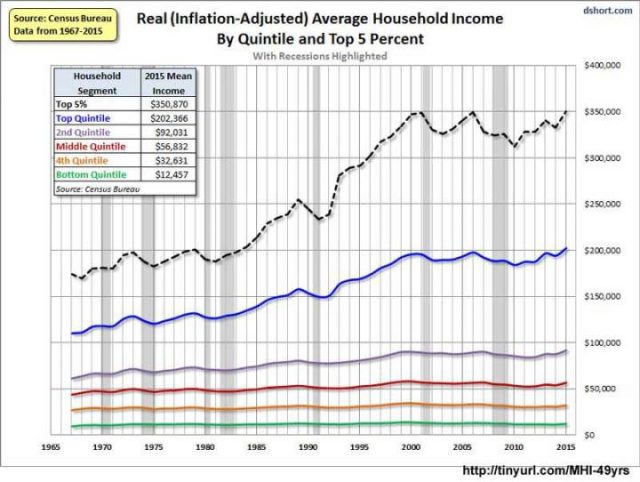
Trotz der guten Nachrichten! und der Anerkennung der ersten Grafik und der so genannten Neuigkeiten der zweiten, sehen wir, wenn wir tiefer schürfen, eine andere Geschichte – die bislang verdeckt ist. Diese Grafik ist das Durchschnitts Haushalt Einkommen der fünf Quintile des Einkommens, plus die Top 5%, so dass die Zahlen ein bisschen anders sind und eine andere Geschichte erzählen.
Man unterteilt die Bevölkerung in fünf Teile (Quintil), dafür stehen die fünf bunten Linien. Die unteren 60% der Familien mit geringen Haushaltseinkommen, die grünen, braunen und roten Linien, haben in realer Kaufkraft seit 1967 praktisch keine Verbesserung erreicht, die Mitte / das Großbürgertum in lila Linie, hat einen moderaten Anstieg gesehen. Nur die besten 20% der Familien (blaue Linie) haben eine solide, stetige Verbesserung erreicht – und wenn wir die Top 5% herausnehmen, die gestrichelte schwarze Linie, sehen wir, dass sie nicht nur den Löwenanteil der US-Dollar verdienen, Sie haben auch prozentual am meisten davon profitiert .
Wo sind die gefühlten Vorteile?
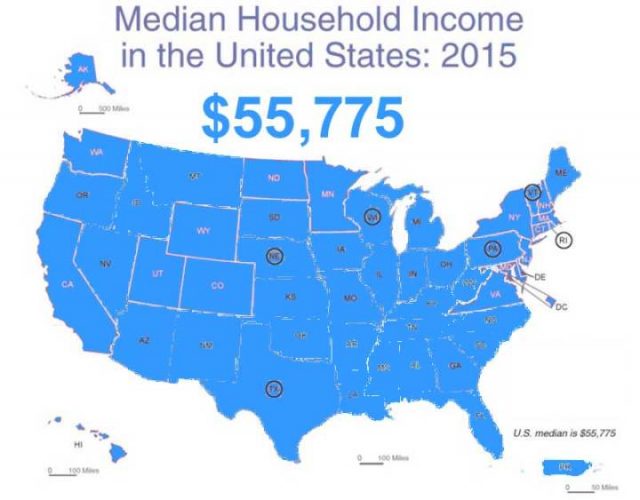
Oben ist, was uns der nationale Durchschnitt mitteilt, die US Median Haushalts Einkommens Metrik. Wenn wir das ein bisschen näher untersuchen, erkennen wir:
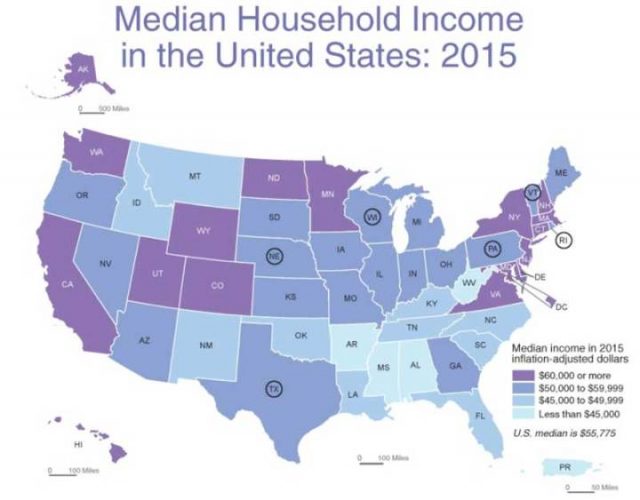
Median Haushaltseinkommen nach Bundesstaaten
Neben einigen Überraschungen, wie Minnesota und North Dakota, zeigt es das, was wir vermuten können. Die Bundesstaaten New York, Massachusetts, Connecticut, New Jersey, Maryland, Virginia, Delaware – kommen alle auf das höchste Niveau des durchschnittlichen Haushaltseinkommen, zusammen mit Kalifornien, Washington. Utah war schon immer die Heimstätte der wohlhabenderen Latter-Day Saints [Kirche Jesu Christi der Heiligen der Letzten Tage] und ist zusammen mit Wyoming und Colorado ein Ruhestand Ziel für die Reichen geworden. Die Bundesstaaten, deren Abkürzungen eingekreist sind, haben Haushalte mit Einkommen in der Nähe des nationalen Medians.
Lassen Sie uns das vertiefen:
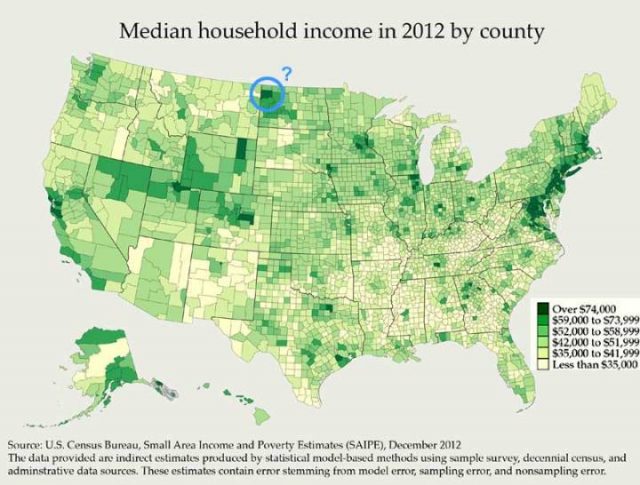
Median Haushaltseinkommen nach Landkreisen
Die dunkleren grünen Kreise haben die höchsten Median Haushaltseinkommen. San Francisco / Silicon Valley im Westen und die Washington DC-bis-New York City-zu-Boston Megapolis im Osten, sind leicht zu erkennen.
Diese Karte beantwortete meine große Frage: Wieso hat North Dakota so ein hohes Median Einkommen? Antwort: Es ist ein Bereich, umkreist und markiert „?“, Zentriert durch Williams County, mit Williston als Hauptstadt. Hier wohnen weniger als 10.000 Familien. Und „Williston sitzt auf der Bakken-Formation, der bis Ende 2012 vorausgesagt wurde, mehr Öl zu produzieren als jeder andere Standort in den Vereinigten Staaten“, es ist das Gebiet von Amerikas neustem Öl-Boom.
Und wo ist das große Geld? Meistens in den großen Städten:
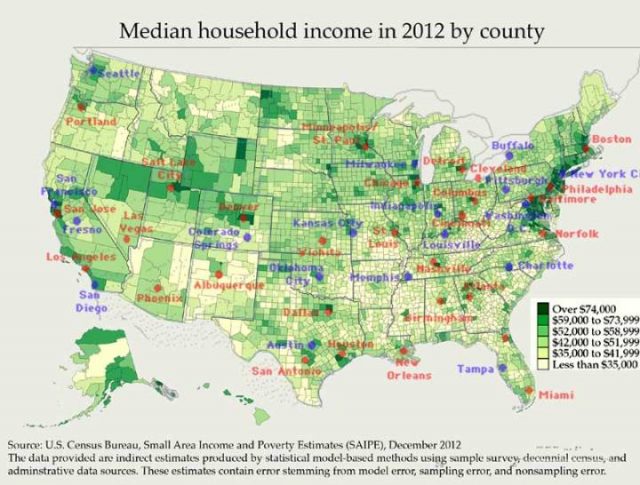
Median Haushaltseinkommen nach Städten
Und wo ist das Geld knapp? Alle jene hellgelben Landkreise sind Gebiete, in denen viele bis die meisten Familien an oder unterhalb der föderalen Armutsgrenze für vierköpfige Familien leben.
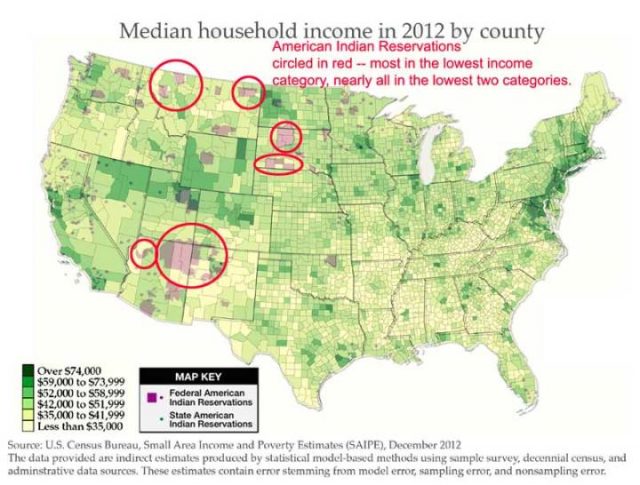
Median niedrigste Haushaltseinkommen nach Landkreisen
Einkommen der restlichen Haushalte
Eine Auswertung der Gebiete der US-Indianer Reservate zeigt, dass diese im Westen vor allem die niedrigsten und zweithöchsten Einkommensgruppen repräsentieren. (Ein eigenes Interesse von mir, mein Vater und seine 10 Brüder und Schwestern wurden in Pine Ridge im südwestlichen South Dakota geboren, das rote Oval.) Man findet viel von dem alten Süden in dem untersten Kreis (hellgelb) und den Wüsten von New Mexico und West Texas und den Hügeln von West Virginia und Kentucky.
Eine weitere Grafik:
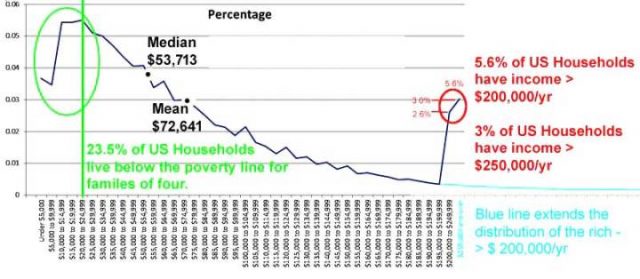
Prozentuale Verteilung der Haushaltseinkommen
Was sagt uns das?
Es sagt uns, dass das nationale Median Haushaltseinkommen, als Einzelwert – vor allem in Dollar, der nicht Inflation bereinigt ist – die Ungleichheiten und Unterschiede, die wichtige Fakten dieser Metrik sind, verdecken. Der Einzelwert des nationalen Median Haushaltseinkommen ergibt nur eine sehr unzureichende Information – es sagt uns nicht, wie amerikanische Familien einkommensmäßig einzuordnen sind. Es informiert uns nicht über das wirtschaftliche Wohlergehen der amerikanischen Familien – vielmehr verbirgt es den wahren Sachverhalt.
Daher sage ich, dass das veröffentlichte durchschnittliche Haushaltseinkommen, anstatt das wirtschaftliche Wohlergehen der amerikanischen Familien zu beleuchten, buchstäblich die wirklichen signifikanten Daten über das Einkommen der amerikanischen Haushalte verbirgt. Wenn wir uns erlauben, von dem Strahl der Verschleierung [Im Original „shines a Beam of Darkness“] verblendet zu werden, die diese Art von Wahrheit versteckenden Durchschnittswerten repräsentieren, dann scheitern wir in unserer Pflicht als kritische Denker.
Bedeutet das, dass Durchschnittswerte schlecht sind?
Nein natürlich nicht. Sie sind nur eine Möglichkeit, eine Reihe von numerischen Daten zu betrachten. Das bietet aber nicht immer die beste Information. Es sei denn, die Daten, die man betrachtet, sind fast normal verteilt und Änderungen werden durch bekannte und verstandene Mechanismen verursacht. Mittelwerte aller Art führen uns häufiger in die Irre und verdecken die Informationen, die wir wirklich betrachten sollten. Durchschnittswerte sind die Ergebnisse von faulen Statistikern und führen selten zu einem besseren Verständnis.
Der häufigste logische und kognitive Fehler ist es, das es das Verständnis beeinflusst, es eine Meinung suggestiert, indem man nur diese eine sehr schmale Sicht auf die Daten anbietet – man muss unbedingt erkennen, dass sich die Information hinter irgendeiner Art von Durchschnitt versteckt und alle anderen verfügbaren Informationen verdeckt und diese damit nicht wirklich repräsentativ für das gesamte, große Bild sein kann.
Es gibt viele bessere Methoden der Darstellung von Daten, wie das vereinfachte Balkendiagramm, das im Beispiel der Schuljungen verwendet wird. Für einfache numerische Datensätze, Diagramme und Grafiken, sind diese oft angemessen, wenn sie verwendet werden, um Informationen zu zeigen, anstelle diese zu verstecken).
Wie Mittelwerte, können auch Visualisierungen von Datensätzen für gute oder schlechte Informationen verwendet werden – die Propaganda durch Nutzung von Datenvisualisierungen, die heutzutage PowerPoint-Folien und Videos beinhalten, ist Legion.
Hüten Sie sich vor jenen, die Mittelwerte wie Schlagstöcke oder Knüppel handhaben, um öffentliche Meinung zu bilden.
Und Klima?
Die Definition des Klimas ist, dass es ein Durchschnitt ist – „diese Wetterbedingungen herrschen in einem Gebiet im allgemeinen oder über einen langen Zeitraum.“ Es gibt keine einzige „Klima Metrik“ – keine einzelner Wert, der uns sagt, was „Klima“ tut.
Mit dieser vorgenannten Definition, zufällig aus dem Internet über Google – gibt es kein Erd-Klima. Die Erde ist kein Klimabereich oder Klimaregion, die Erde hat Klimaregionen, ist aber kein Klimabereich.
Wie in Teil 1 erörtert, müssen die im Durchschnitt gemittelten Objekte in Sätzen homogen und nicht so heterogen sein, dass sie inkommensurabel sind. So werden bei der Erörterung des Klimas einer Region mit vier Jahreszeiten, Allgemeinheiten über die Jahreszeiten gemacht, um die klimatischen Bedingungen in dieser Region im Sommer, Winter, Frühjahr und Herbst einzeln darzustellen. Eine durchschnittliche Tagestemperatur ist keine nützliche Information für Sommerreisende, wenn der Durchschnitt für das ganze Jahr einschließlich der Wintertage genommen wird – solch eine durchschnittliche Temperatur ist Torheit aus pragmatischer Sicht.
Ist es aus der Sicht der Klimawissenschaft ebenfalls Dummheit? Dieses Thema wird in Teil 3 dieser Serie behandelt.
Schlussfolgerung:
Es reicht nicht aus, den Durchschnitt eines Datensatzes korrekt mathematisch zu berechnen.
Es reicht nicht aus, die Methoden zu verteidigen, die Ihr Team verwendet, um die [oft-mehr-missbrauchten-als-nicht] globalen Mittelwerte von Datensätzen zu berechnen.
Auch wenn diese Mittelwerte von homogenen Daten und Objekten sind und physisch und logisch korrekt sind, ein Mittelwert ergibt eine einzelne Zahl und kann nur fälschlicherweise als summarische oder gerechte Darstellung des ganzen Satzes, der ganzen Information angenommen werden.
Durchschnittswerte, in jedem und allen Fällen, geben natürlicherweise nur einen sehr eingeschränkten Blick auf die Informationen in einem Datensatz – und wenn sie als Repräsentation des Ganzen akzeptiert werden, wird sie als Mittel der Verschleierung fungieren, die den Großteil verdecken und die Information verbergen. Daher, anstatt uns zu einem besseren Verständnis zu führen, können sie unser Verständnis des zu untersuchenden Themas reduzieren.
Durchschnitte sind gute Werkzeuge, aber wie Hämmer oder Sägen müssen sie korrekt verwendet werden, um wertvolle und nützliche Ergebnisse zu produzieren. Durch den Missbrauch von Durchschnittswerten verringert sich das Verständnis des Themas eher, als das es die Realität abbildet.
Erschienen auf WUWT am 19.06.2017
Übersetzt durch Andreas Demmig
https://wattsupwiththat.com/2017/06/19/the-laws-of-averages-part-2-a-beam-of-darkness/
Für unsere Leser in Deutschland, hier eine Grafik des statistischen Bundesamtes
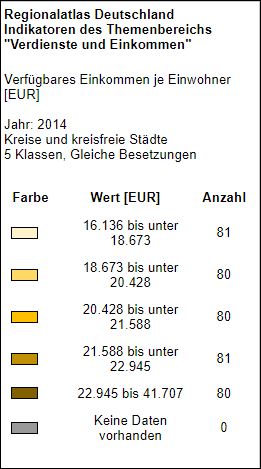
© Statistischen Ämter des Bundes und der Länder, Deutschland, 2017. Dieses Werk ist lizensiert unter der Datenlizenz Deutschland – Namensnennung – Version 2.0.
# # # #
Dieses Essay wird länger – und ist am besten solange gespeichert, bis Sie Zeit haben, es in seiner Gesamtheit zu lesen. Das Warten lohnt sich und die eventuelle Anstrengung.
Es kommt in drei Abschnitten: eine Einführung in Durchschnittswerte, eine allgemeine Diskussion über Metriken von Obstsalaten und eine eingehendere Diskussion über ein Beispiel mit einer veröffentlichten Studie.
NB: Während dieser Aufsatz als Beispiel eine ziemlich aktuelle Studie von Catherine M. O’Reilly, Sapna Sharma, Derek K. Grey und Stephanie E. Hampton anführt, mit dem Titel „Schnelle und sehr variable Erwärmung der Oberfläche Wasser in Seen rund um den Globus “
(.pdf hier; Poster hier, AGU Meeting Video-Präsentation hier) [der American Geophysical Union],
ist es nicht meine Absicht, die Studie [das paper] zu kritisieren – ich werde das anderen mit einem direkten Interesse überlassen. Mein Interesse liegt in den logischen und wissenschaftlichen Fehlern, den Informationsfehlern, die aus dem resultieren können, was ich spielerisch geprägt habe „Das erste Gesetz der Mittelwerte“.
Durchschnittswerte: Eine „erste Einführung“
Sowohl das Wort als auch das Konzept „Durchschnitt“ sind in der breiten Öffentlichkeit sehr viel Verwirrung und Missverständnis unterworfen und sowohl als Wort als auch im Kontext ist eine überwältigende Menge an „lockerem Gebrauch“ auch in wissenschaftlichen Kreisen zu finden, ohne die Peer-Reviewed-Artikel in Zeitschriften und wissenschaftlichen Pressemitteilungen auszuschließen. Lassen Sie uns eine kurze Einführung absolvieren oder eine Auffrischung zum Durchschnitt (die cognizanti = die „sich darüber im Klaren sind“, können direkt nach unten zu Obstsalat scrollen).

Und natürlich das Verb „bedeuten“, um mathematisch einen Durchschnitt zu berechnen, wie im „Durchschnitt“. Da gibt es drei Haupttypen von „Durchschnittswerten“ gibt – der Modus, der Median und das Mittel – ein kurzer Blick auf diese:



Mehrere dieser Definitionen beziehen sich auf „einen Satz von Daten“ … In der Mathematik ist ein Satz eine wohldefinierte Sammlung von verschiedenen Objekten, die als ein Objekt in ihrem eigenen „Recht“ betrachtet werden [Zugehörigkeit, Eigenschaft; Lage, Art, … usw.]. (Z. B. sind die Zahlen 2, 4 und 6 verschiedene Objekte wenn sie getrennt betrachtet werden, aber wenn sie zusammen betrachtet werden, bilden sie einen einzigen Satz der Größe drei, geschrieben {2,4,6}.)
Dieses Bild fasst die drei verschiedenen gemeinsamen Mittelwerte zusammen:
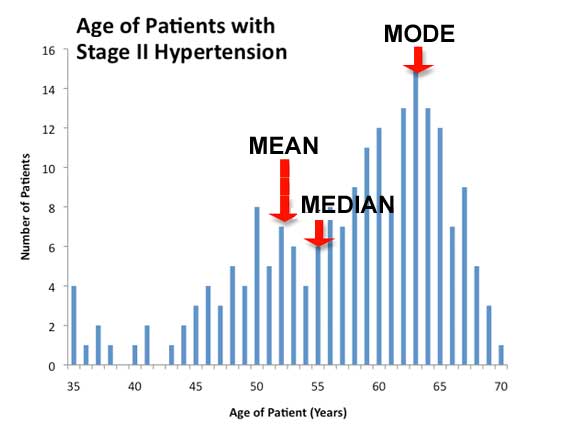
[Alter der Patienten mit Bluthochdruck, Stufe II]
Hier sehen wir das Alter, bei dem die Patienten Stufe II Hypertonie (schwerer HBP – hoher Blutdruck) entwickeln entlang der x-Achse und die Anzahl der Patienten [die daran leiden] entlang der linken vertikalen Achse (y-Achse). Dieses Balkendiagramm oder Histogramm zeigt, dass einige Patienten HBP ziemlich jung entwickeln, in ihren späten 30 und 40ern, nach 45 erhöht sich die Inzidenz mehr oder weniger stetig mit fortschreitendem Alter bis zur Mitte der 60er Jahre, danach fällt die Inzidenz [die Anzahl der Betroffenen] ab. Wir sehen, was eine schiefe Verteilung genannt wird, schief nach rechts. Diese Schande (rechts oder links) ist typisch für viele reale Weltverteilungen. [also nicht gleichmäßig oder Gaußsche Verteilungskurve; Einschub des Übersetzers]
Was wir normalerweise den Durchschnitt nennen würden, der Mittelwert, berechnet durch das Zusammenfügen aller Altersstufen der Patienten, bei denen sich HBP entwickelt hat und die Teilung durch die Gesamtanzahl der Patienten – obwohl mathematisch korrekt, ist das klinisch nicht sehr informativ. Es ist wahr, dass das mittlere Alter für die Entwicklung von HPB bei etwa 52 Jahre liegt, ist es weit häufiger, HPB in den späten 50er bis Mitte der 60er Jahre zu entwickeln. Es gibt medizinische Gründe für diese Verschiebung der Daten – aber für unsere Zwecke ist es genug zu wissen, dass jene Patienten, die HPB im jüngeren Alter entwickeln, den Mittelwert verschieben – ignorieren wir die Ausreißer auf der linken Seite, würde das das Mittel mehr in Einklang mit den tatsächlichen Inzidenz Zahlen bringen.
Medizinisch gesehen, weist dieses Histogramm darauf hin, dass es zwei verschiedene Ursachen oder Krankheitswege für HPB geben kann. Eine, die mit einem frühen Beginn für HPB und eine im Zusammenhang mit fortschreitendem Alter, manchmal auch als später hoher Blutdruck bekannt.
(In diesem Beispiel ist das Median Alter für HPB überhaupt nicht sehr informativ.)
Unser HPB-Beispiel kann gelesen werden als „Im Allgemeinen, beginnt das reale Risiko, HPB zu bekommen, in der Mitte der 40er Jahre und das Risiko steigt weiter bis zur Mitte der 60er Jahre. Wenn Sie HPB nicht um 65 oder so entwickelt haben, verringert sich Ihr Risiko mit zusätzlichen Jahren, obwohl Sie noch wachsam sein müssen. “
Unterschiedliche Datensätze haben unterschiedliche Informationswerte für die verschiedenen Arten von Durchschnittswerten.
Hauspreise [Immobilien] für eine Gegend werden oft als Mediane Hauspreise zitiert. Wenn wir den Mittelwert betrachteten, würde der Durchschnitt von den Häusern, die von den reichsten 1% der Bevölkerung bevorzugt werden, nach oben geschoben werden, d.h. Häuser, die in Millionen Dollar gemessen werden (siehe hier und hier, und hier).
Aktienmärkte werden oft durch Dinge wie dem Dow Jones Industrial Average (DJIA) beurteilt [ein preisgewichteter Durchschnitt von 30 bedeutenden Aktien, die an der New Yorker Börse (NYSE) und der NASDAQ gehandelt wurden und von Charles Dow im Jahre 1896 erfunden wurden]. Ein gewichteter Durchschnitt ist ein Mittelwert, der durch die gegebenen Werte in einem Datensatz mit mehr Einfluss nach einem Attribut der Daten berechnet wird. Es ist ein Durchschnitt, in dem jeder durchschnittlichen Menge ein Gewicht zugewiesen wird, und diese Gewichtungen bestimmen die relative Wichtigkeit jeder Menge im Durchschnitt. Der S & P 500 ist ein Börsenindex, der die 500 am meisten gehaltenen Aktien an der New Yorker Börse oder NASDAQ verfolgt. [Ein Aktienindex … ist ein Maß für den Wert eines Teils der Börse. Es wird aus den Preisen ausgewählter Bestände berechnet, in der Regel ein gewichteter Durchschnitt.]
Familieneinkommen werden von der US Census Bureau [statistisches Amt] jährlich als das „Median Household Income“ für die Vereinigten Staaten gemeldet [$ 55.775 im Jahr 2015].
Lebenserwartung wird von verschiedenen internationalen Organisationen als „durchschnittliche Lebenserwartung bei der Geburt“ gemeldet (weltweit war es 71,0 Jahre über den Zeitraum 2010-2013). „Mathematisch ist die Lebenserwartung die mittlere Anzahl von Lebensjahren, die in einem gegebenen Alter noch verbleiben, vorausgesetzt, dass die altersbedingten Sterblichkeitsraten bei ihren zuletzt gemessenen Werten bleiben. … Darüber hinaus, weil die Lebenserwartung ein Durchschnitt ist, kann eine bestimmte Person viele Jahre vorher oder viele Jahre nach dem „erwarteten“ Überleben sterben. “ (Wiki).
Such man mit einer der großen Internet-Suchmaschinen nach Phrasen, einschließlich des Wortes „Durchschnitt“ wie „durchschnittliche Kosten für ein Brot“, „durchschnittliche Größe von 12-jährigen Kindern“ kann man sich stundenlang unterhalten.
Allerdings ist es zweifelhaft, dass Sie danach als Ergebnis mehr wissen als vorher.
Diese Reihe von Essays ist ein Versuch, diesen letzten Punkt zu beantworten: Warum wissen Sie nach dem Lesen von Durchschnitten nicht mehr als vorher?
Obstsalat
Wir haben alle schon mal Vergleiche von Äpfeln mit Birnen gesehen.
[Amerikaner nehmen andere Früchte für unzulässige Vergleiche: Äpfel mit Orangen, daher geht es nun weiter mit Orangen, der Abwechslung wegen, tippe ich auch mal Fruchtsalat anstatt Obstsalat, der Übersetzer]

Dinge die man vergleicht, müssen homogen genug sein, um vergleichbar zu sein und nicht so heterogen, dass sie so nicht zusammen verglichen werden können.


Probleme treten sowohl physisch als auch logisch auf, wenn Versuche unternommen werden, „Mittelwerte“ von nicht vergleichbaren oder inkommensurablen Objekten zu finden – Objekte und / oder Messungen, die nicht logisch oder physisch (wissenschaftlich) zum selben „Satz“ gehören.
Die Diskussion von Datensätzen für Amerikaner, die in den 40er und 50er Jahren zur Schule gingen, kann für diese verwirrend sein. Später aber, wurden jüngere Amerikaner den Begriffen von Datensätzen frühzeitig ausgesetzt. Für unsere Zwecke können wir eine einfache Definition einer Sammlung von Daten über eine Anzahl ähnlicher, vergleichbarer, gleichartiger, homogener Objekte verwenden und bei einem Datensatz sind die Daten selbst vergleichbar und [liegen] in kompatiblen Messeinheiten vor. (Viele Datensätze enthalten viele Untermengen von verschiedenen Informationen über denselben Satz von Objekten. Ein Datensatz über eine Studie von Eastern Chipmunks [Streifenbackenhörnchen] kann Sub-Sets wie Höhe, Gewicht, geschätztes Alter usw. enthalten. Die Untermengen müssen Intern homogen sein – so wie „alle Gewichte in Gramm“.)
Man kann nicht das Gewicht mit dem Geschmack eines Korbes von Äpfeln vergleichen. Gewicht und Geschmack sind nicht vergleichbare Werte. Auch kann man das Gewicht nicht mit der Farbe der Bananen vergleichen.
Ebenso kann man die Höhe / Länge von Einzelnen in einer Zusammenstellung nicht logisch „mitteln“, wie „alle Tiere, die im zusammenhängenden nordamerikanischen Kontinent leben (als da sind USA, Kanada und Mexiko)“ Warum? Neben der Schwierigkeit beim Sammeln eines solchen Datensatzes, obwohl die Messungen alle in Zentimeter (ganze oder Teile davon) sein können, ist „alle Tiere“ kein logischer Satz von Objekten bei der Betrachtung von Höhe / Länge.
Ein solcher Datensatz, würde alle Tiere von Bison, Elch und Kodiakbären über Rinder, Hirsche, Hunde, Katzen, Waschbären, Nagetiere, Würmer, Insekten aller Arten, multizelluläre, aber mikroskopisch kleine Tiere und einzellige Lebewesen enthalten. In unserem ausgewählten geographischen Gebiet gibt es (sehr sehr grob) geschätzte 1 quintillion fünfhundert quadrillionen (1.500.000.000.000.000.000 [1,5 x10^18]) allein an Insekten.
Es gibt nur 500 Millionen Menschen, 122 Millionen Rinder, 83 Millionen Schweine und 10 Millionen Schafe in der gleichen Gegend. Insekten sind klein und viele in der Anzahl und einige Säugetiere sind vergleichsweise groß aber wenige in der Anzahl. Uni- und multizelluläre mikroskopische Tiere? Jeder der 500 Millionen Menschen hat im Durchschnitt über 100 Billionen (100.000.000.000.000) Mikroben in und an ihrem Körper. Bei jeder Methode – Mittelwert, Median oder Modus – würde die durchschnittliche Höhe / Länge aller nordamerikanischen Tiere buchstäblich etwas verschwinden – so klein, dass man „im Durchschnitt“ nicht erwarten würde, dass man „Tiere“ mit bloßen Augen sehen kann.
Um einen Durchschnitt eines beliebigen Typs zu berechnen, der physisch, wissenschaftlich sinnvoll und logisch und nützlich ist, muss der gemittelte Datensatz selbst eine vergleichbare, ange-messenbare, homogene Sammlung von Objekten sein, mit Daten über diese Objekte, die vergleichbar und angemessen sind.
Wie ich später besprechen werde, gibt es Fälle, in denen die Sammlung (der Datensatz) richtig und vernünftig erscheint, die Daten über die Sammlung scheinen vergleichbare Einheiten zu sein und doch entpuppt sich der daraus resultierende Durchschnitt als nicht-physisch – es macht keinen Sinn in Bezug auf Physik oder Logik.
Diese Arten von Durchschnittswerten, von ungleichartigen, heterogenen Datensätzen, in denen entweder die Messungen oder die Objekte selbst inkommensurabel sind – wie Vergleiche von Äpfeln und mit Orangen und mit Bananen – geben Sie die Ergebnisse, die als Fruchtsalat bezeichnet werden können und haben Anwendbarkeit und Bedeutung, die von sehr verschieden bis nur gering über unsinnig bis überhaupt nicht reicht.
„Der Klimawandel erwärmt die Seen der Welt rapide“
Dies wird als der wesentliche Punkt einer Studie von Catherine M. O’Reilly, Sapna Sharma, Derek K. Grey und Stephanie E. Hampton herausgestellt,
mit dem Titel “Rapid and highly variable warming of lake surface waters around the globe” [ .pdf hier; poster hier, AGU Video Präsentation des Meetings hier ].
[„Schnelle und sehr variable Erwärmung von Seewasserflächen rund um den Globus“, AGU American Geophysical Union]
Es ist bemerkenswert, dass die Studie ein Ergebnis der Global Lake Temperature Collaboration (GLTC) ist, die besagt: „Diese Erkenntnisse, die Notwendigkeit der Synthese von Vor-Ort- und Fernerkundungsdatensätzen und die anhaltende Bestätigung, dass der globale und regionale Klimawandel wichtige Auswirkungen auf Terrestrische und aquatische Ökosysteme hat, ist die Motivation hinter der Global Lake Temperature Collaboration. “
Die AGU-Pressemitteilung zu dieser Studie beginnt mit: „Der Klimawandel erwärmt die Seen der ganzen Welt rapide, bedroht die Süßwasser- und Ökosysteme, nach einer neuen Studie über sechs Kontinente.“
„Diese Studie, die von der NASA und der National Science Foundation gefördert wurde, fand Seen, die durchschnittlich um 0,61 Grad Fahrenheit (0,34 Grad Celsius) jedes Jahrzehnt erwärmt wurden. Das ist mehr als die Erwärmungsrate des Ozeans oder der Atmosphäre und es kann tiefgreifende Effekte haben, sagen die Wissenschaftler. „
Darauf folgen die „beängstigenden“ – wenn dieser Trend fortfährt – Szenarien.
Nirgendwo in der Pressemitteilung wird angegeben, was tatsächlich gemessen, gemittelt und gemeldet wird. (Siehe „Was zählen sie wirklich?„)
Also, was wird gemessen und berichtet? Am Beginn der AGU Video-Präsentation, sagen Simon Hook, von JPL und einer der Co-Autoren, in der Frage & Antwort Runde aus, dass „das sommernächtliche Oberflächentemperaturen sind.“
Lassen Sie mich noch deutlicher sein – das sind sommerliche, nächtliche Temperaturen der Wasser-(Haut-) Oberfläche wie in „Die SST [Sea surface temperature – See Oberflächen …] direkt an der Oberfläche heißt „Haut SST“ und kann sich deutlich von der Masse der SST unterscheiden, vor allem bei schwachen Winden und hohen Mengen an auftreffendem Sonnenlicht …. Satelliten-Instrumente, die im Infrarot-Teil des Spektrums messen, messen im Prinzip die „Haut SST“. „[Quelle]
Bei weiterem nachhaken, erklärt Simon Hook weiter, dass die Temperaturen in der Studie, stark beeinflusst durch Satelliten-Messungen sind, da die Daten zum großen Teil Satelliten-Daten sind , nur sehr wenig Daten sind eigentlich in situ [„an ihrer ursprünglichen Stelle oder in der Position“ – von Hand oder per Boje, zum Beispiel] gemessen worden. Diese Information steht natürlich auch für diejenigen zur Verfügung, die die ganze Studie lesen und sorgfältig durch die ergänzenden Informationen und Datensätze gehen – aber es wird durch die Abhängigkeit von der Aussage verdeckt, die immer wiederholt: „die Seen erwärmen sich durchschnittlich jedes Jahrzehnt um 0,61 Grad Fahrenheit (0,34 Grad) Celsius).“
Welche Art von Durchschnitt? Äpfel und Orangen und Bananen – gibt Fruchtsalat.
Dies ist die Karte der untersuchten Seen:
Man muss kein See-Experte sein, um zu erkennen, dass diese Seen von den Großen Seen in Nordamerika und bis zum Tanganjika-See in Afrika und zum Lake Tahoe in den Sierra Nevada Mountains an der Grenze von Kalifornien und Nevada reichen. Einige Seen sind kleiner und flach, einige Seen sind riesig und tief, einige Seen sind in der Arktis und manche sind in den Wüsten, einige Seen sind mit Eis bedeckt, und einige Seen sind noch nie zugefroren, einige Seen erhalten Schmelzwasser und einige werden von langsam fließenden Äquatorflüssen gespeist.
Natürlich würden wir davon ausgehen, dass, wie die Land Oberflächentemperatur und die Meeres Oberflächentemperatur, der Durchschnitt der See Wasser Temperatur in dieser Studie durch die See Oberfläche gewichtet wird. Nein ist es nicht. Jeder See in der Studie ist gleichwertig, egal wie klein oder groß, wie tief oder wie flach, Schnee gefüttert oder Fluss gespeist. Da die überwiegende Mehrheit der Studiendaten aus Satellitenbeobachtungen stammt, sind die Seen alle „größer“, kleine Seen, wie der Stausee für meine Wasserversorgung, werden durch den Satellit nicht leicht erkannt.
Also, was haben wir davon, wenn wir die [nächtliche Hautoberfläche in der Sommerzeit] Wassertemperatur von 235 heterogenen Seen „durchschnittlich“ vergleichen“ Wir bekommen einen Obstsalat – eine Metrik, die mathematisch korrekt ist, aber physisch und logisch weit von jeder Nutzung entfernt ist [außer für Propagandazwecke].
Dies wird in der Zusammenfassung der Studie frei eingestanden, die wir uns fragmentarisch anschauen können: [zitierte Zusammenfassung in Kursivschrift]
„Die hohe räumliche Heterogenität der in dieser Studie gefundenen See-Erwärmungs-Raten stehen im Widerspruch zur üblichen Annahme der allgemeinen regionalen Kohärenz.“
Seen reagieren regional nicht auf eine einzige Ursache – wie „globale Erwärmung“. Seen in der Nähe von einander oder in einer definierten Umweltregion sind nicht notwendigerweise in ähnlicher Weise oder aus dem gleichen Grund erwärmt, und einige benachbarte Seen haben entgegengesetzte Zeichen der Temperaturänderung. Die Studie widerlegt die Erwartung des Forschers, dass die regionale Oberflächen-Temperaturerwärmung der regionalen See-Erwärmung entsprechen würde. Nicht so.
„Seen, deren Erwärmungsraten ähnlich waren, in Verbindung mit bestimmten geomorphen oder klimatischen Prädiktoren (dh., Seen innerhalb eines „Blattes“ [der Übersicht; ~ Umgebungsbedingungen]), (siehe die Studie für das Übersichtsdiagramm), zeigten eine nur eine schwache geographische Gruppierung (Abbildung 3b), im Gegensatz zu früheren Schlussfolgerungen der regional – skalierten, räumlichen Kohärenz [~ Zusammenhängen] in den Seen-Erwärmungs-Trends [Palmer et al., 2014; Wagner et al., 2012]. „
Seen erwärmen sich geomorph (nach der Form der Landschaft und anderen natürlichen Eigenschaften der Erdoberfläche) und dem lokalen Klima – nicht regional, sondern individuell. Diese Heterogenität impliziert das Fehlen einer einzigen oder sogar ähnlicher Ursachen innerhalb der Regionen. Mangel an Heterogenität bedeutet, dass diese Seen nicht als ein einziger [zusammenhängender] Datensatz betrachtet werden sollten und es deshalb keinen Sinn macht, diese zu mitteln.
„In der Tat, ähnlich reagierende Seen waren weitgehend auf der ganzen Welt verteilt, was darauf hinweist, dass die Eigenschaften der Seen, Klima-Effekte stark vermitteln können.“
Weltweit gesehen, sind Seen im Zusammenhang mit der Oberflächenwassertemperatur kein physikalisch sinnvoller Datensatz.
„Die Heterogenität in den Erwärmungsraten der Oberflächen unterstreicht die Bedeutung der Berücksichtigung von Wechselwirkungen zwischen Klima und geomorphen Faktoren, die die Seen zu Reaktionen antreiben und einfache Aussagen über Oberflächenwassertrends verhindern; Man kann nicht davon ausgehen, dass jeder einzelne See sich gleichzeitig mit der Lufttemperatur erwärmt hat oder dass alle Seen in einer Region sich gleich erwärmen. „
Auch hier ist ihre Schlussfolgerung, dass die Seen weltweit kein physikalisch sinnvoller Datensatz im Zusammenhang mit der Oberflächenwassertemperatur sind, aber sie bestehen darauf, einen einfachen Durchschnitt zu finden, das heißt, die darauffolgenden Schlussfolgerungen und Warnungen zu diesem Mittelwert.
„Die Vorhersage der zukünftigen Reaktionen der Seeökosysteme auf den Klimawandel beruht darauf, die Natur solcher Wechselwirkungen zu identifizieren und zu verstehen.“
Die überraschende Schlussfolgerung zeigt, dass, wenn sie herausfinden wollen, was die Temperatur eines bestimmten Sees betrifft, müssen sie diesen See und sein lokales Ökosystem für die Ursachen jeder Veränderung studieren.
Ein mutiger Versuch wurde gemacht, diese Studie mit Ad-hoc-Schlussfolgerungen zu retten – aber die meisten geben einfach zu, dass ihre ursprüngliche Hypothese von „Globale Erwärmung verursacht weltweite Erwärmung von Seen“ entkräftet wurde. Seen (zumindest die sommernächtlichen Oberflächentemperaturen der Seen) können sich erwärmen, aber sie erwärmen sich nicht noch nicht mal mit den Lufttemperaturen, und nicht zuverlässig im Gleichklang mit anderen besonderen geomorphen oder klimatischen Faktoren, und nicht unbedingt wärmer werdend, auch wenn die Lufttemperaturen vor Ort steigen Zwangsläufig fallen die Forscher auf die „durchschnittliche“ Metrik der Wärme der Seen zurück.
Diese Studie ist ein gutes Beispiel dafür, was passiert, wenn die Wissenschaftler versuchen, Mittelwerte für Dinge zu finden, die unähnlich sind – so unähnlich, dass sie nicht in das gleiche „Set“ gehören. Man kann es mathematisch machen – alle Zahlen sind zumindest in den gleichen Einheiten von Grad C oder F – aber solche Mittelwerte geben Ergebnisse, die nicht-physisch und unsinnig sind – ein Obstsalat, der aus dem Versuch besteht, diesen als Durchschnitt von Äpfel und Orangen und Bananen zu beschreiben.
Darüber hinaus können die Obstsalat-Mittelwerte nicht nur in die Irre führen, sondern sie verdecken mehr Informationen als sie erhellen, wie sich aus dem Vergleich der vereinfachten Pressemitteilung deutlich ergibt. „Seen erwärmen sich durchschnittlich um 0,61 Grad Fahrenheit (0,34 Grad Celsius) je Jahrzehnt“ zu den tatsächlichen, wissenschaftlich gültigeren Erkenntnissen der Studie, die zeigen, dass sich die Temperatur eines jeden Sees aufgrund lokaler, manchmal sogar individueller, geomorpher und klimatischer Bedingungen für jeden See ändert und damit Zweifel an der Idee globaler oder regionaler Ursachen nährt.
Ein weiteres Beispiel für eine Fruchtsalat-Metrik wurde in meinem schon länger zurückliegenden Baked Alaska? Essay [Kocht Alaska] gezeigt. Der den logischen und wissenschaftlichen Irrtum der Temperatur von Alaska als Einheit, den „Staat Alaska“, als eine politische „Abteilung“ hervorgehoben hat, obwohl Alaska, das sehr groß ist, aus 13 verschiedenen unterschiedlichen Regionen besteht, die sich mit unterschiedlichen Raten erwärmen und kühlen (und offensichtlich mit verschiedenen Anzeichen) über unterschiedliche Zeiträume. Diese wichtigen Details sind alle verloren, verdeckt, durch den staatlichen Durchschnitt.
Das Entscheidende:
Sorgfältige kritische Denker werden auf der Hut sein bei Zahlen, die, obwohl sie Ergebnisse einer einfachen Hinzufügung und Teilung sind, in der Tat Obstsalat Metriken sind, mit wenig oder keiner wirklichen Bedeutung oder mit Bedeutungen, weit anders als die, für die sie angeführt werden.
Man sollte mit großer Sorgfalt prüfen, ob die Zahl, die als Durchschnitt dargestellt wird, tatsächlich das Ergebnis darstellt, für das sie beansprucht wird. Durchschnittswerte haben am häufigsten nur eine sehr begrenzte Anwendbarkeit, da sie die Details verdecken, die oft die viel wichtigere Wirklichkeit enthüllen [was das Thema des nächsten Aufsatzes in dieser Serie ist).
# # # # #
Hinweis auf LOTI, HadCRUT4, etc .: Es ist meine persönliche Meinung, dass alle kombinierten Land und See Oberflächen Temperatur Metriken, und wie sie alle genannt werden, einschließlich derer, die als Indizes, Anomalien und „Vorhersagen der kleinsten Fehlerbandbreite“, genau diese Art von durchschnittlichem Obstsalat sind. In der Physik, wenn nicht Klimawissenschaft, ist die Temperaturänderung ein Indikator für die Veränderung der Wärmeenergie eines Objekts (z. B. eines bestimmten Luft- oder Meerwasservolumens). Um einen gültigen Mittelwert von Mischluft- und Wassertemperaturen zu berechnen, muss der Datensatz zunächst gleiche Einheiten für gleichwertige Volumina gleichen Materials enthalten (die automatisch alle Datensätze von Meeres-Oberflächenhaut-Temperaturen, die volumenlos sind) ausschließt.
Die Temperaturen unterschiedlicher Volumina von unterschiedlichen Materialien, auch Luft, mit unterschiedlicher Feuchtigkeit und Dichte, können nicht gültig gemittelt werden, ohne in einen Satz von Temperatur-Äquivalent-Einheiten der Wärmeenergie für dieses Material nach Volumen umgewandelt zu werden. Luft und Wasser (und Stein- und Straßenoberflächen und gepflügte Felder) haben viele unterschiedliche spezifische Wärmekapazitäten, so dass eine 1 ° C Temperaturänderung gleicher Volumina dieser unterschiedlichen Materialien sehr unterschiedliche Änderungen der thermischen Energie darstellt. Meeresoberfläche (Haut oder Masse) Temperaturen können nicht mit Oberflächenlufttemperaturen gemittelt werden, um eine physikalisch korrekte Darstellung zu erzeugen, die als Änderung der thermischen (Wärme-) Energie beansprucht wird – die beiden Datensätze sind inkommensurabel und solche Mittelwerte sind Obstsalat.
Und doch sehen wir jeden Tag, dass diese Oberflächentemperatur-Metriken in genau jener nicht-physikalischen Weise dargestellt sind – als ob sie der quantitative Beweis für eine zunehmende oder abnehmende Energie [-beinhaltung] des Erdklimasystems sind. Dies bedeutet nicht, dass korrekt gemessene Lufttemperaturen bei 2 Metern über der Oberfläche und Oberflächen-Meerwassertemperaturen (Masse – da Argo [Messboje] in bestimmten Tiefen schwimmt) uns nicht etwas sagen kann, aber wir müssen sehr sorgfältig bedenken, was sie uns erzählen. Die getrennten Mittelwerte dieser Datensätze werden dennoch immer noch allen Fallstricken und Qualifikationen unterworfen, die in dieser Reihe von Essays vorgestellt werden.
Unser häufiger Kommentator, Steven Mosher, hat kürzlich kommentiert:
„Die globale Temperatur existiert. Sie hat eine genaue physikalische Bedeutung. Es ist die Bedeutung, die uns sagen kann …
In der „kleinen Eiszeit“ war es kühler als heute … es ist die Mittelung, die es uns erlaubt zu sagen, die Tagesseite des Planeten, ist wärmer als die Nachtseite … Die gleiche Mittelung, die uns erlaubt zu sagen, dass Pluto kühler ist als die Erde und der Merkur ist wärmer. „
Ich muss sagen, dass ich mit seiner Aussage einverstanden bin – und wenn Klimawissenschaftler ihre Ansprüche auf verschiedene Global-Temperatur-Durchschnittswerte auf diese drei Konzepte beschränken würden, würden ihren Behauptungen weitaus wissenschaftlicher sein.
NB: Ich glaube nicht, dass es richtig ist zu sagen: „Es hat eine genaue physikalische Bedeutung.“ Es kann eine genaue Beschreibung sein, aber was es für das Klima der Erde bedeutet, ist bei weitem nicht sicher und wird auch nicht präziser durch irgendwelche Messungen.
Ich erwarte, dass Ihre Meinungen zu diesem Thema variieren können.
# # # # #
Erschienen auf WUWT am 14.06.2017
Übersetzt durch Andreas Demmig
Teil 2 und 3 folgen nach

Die Globale-Erwärmung-Angst basiert auf der vermeintlich raschen Erwärmung an der Erdoberfläche, zu der es in den beiden Jahrzehnten zwischen 1978 und 1997 gekommen war. Die Klimamodelle werden mit dieser Erwärmung frisiert und spekulative menschliche Gründe zu deren Erklärung angegeben. Dann wird diese Erwärmung einfach in die Zukunft projiziert, wo sie ein gefährliches Niveau erreicht, und damit wird die Angst erzeugt.
Aber die Satelliten zeigen keine Erwärmung in der Atmosphäre während dieses Zeitraumes, wie es der Fall sein sollte, falls die Erwärmung wirklich Treibhausgasen geschuldet ist. Die Satelliten zeigen während dieser entscheidenden Zeit überhaupt keine Erwärmung. Diese Null-Erwärmung zeigt sehr nachdrücklich, dass die statistischen Modelle bzgl. der Erdoberfläche falsch sind.
Man behalte im Hinterkopf, dass diese globale Temperaturstatistik nicht anders ist als eine Umfrage vor Wahlen, und wir wissen, wie falsch die Ergebnisse einer solchen sein können. Eine unglaublich kleine Untermenge der Gesamtbevölkerung wird befragt. In diesem Falle steht die Gesamtbevölkerung für die Temperatur an jedem Ort der Erde zu jedem Zeitpunkt über ein ganzes Jahr.
Die die Umfrage Durchführenden wissen, dass viel falsch laufen kann. Offenbar wissen die Alarmisten dies nicht, welche diese kruden Temperaturschätzungen als präzise Fakten verkaufen – oder sie entscheiden sich dafür, die Temperaturwerte zu erfinden [to fake it].
In diesen statistischen Modellen stecken mindestens zehn grobe Fehler. Diese Fehler stützen die Ansicht, dass diese kruden Temperaturschätzungen einfach falsch sind. Einige Fehler sind gut bekannt, wie etwa willkürliche Adjustierungen und der städtische Wärmeinsel-Effekt. Andere Schwächen sind nicht so bekannt, wie lokale Wärme-Beeinflussungen, Verfahren der Mittelung über ein Gebiet und Interpolation oder die Verwendung von Meerwasser-Proxys – oder man verkauft den mittleren Wert einfach als wahr, obwohl wir wissen, dass das nicht stimmt. All dies wird Gegenstand späterer Analysen sein.
Aber hier möchte ich den größten Fehler ansprechen, über den nur sehr wenig diskutiert wird. Die statistischen Modelle operieren mit etwas, dass in der Statistik als die „Verfügbarkeit“ oder „Angemessenheit“ einer Stichprobe bezeichnet wird [„availability“ or „convenience“].
Zunächst beachte man, dass die Alarmisten behaupten, die globale Temperatur bis auf ein hundertstel Grad genau zu kennen. Dazu folgendes Beispiel aus dem jüngsten Global Climate Report der NOAA für das Jahr 2016:
„Die mittlere globale Temperatur über Festlands- und Ozean-Gebieten lag im Jahre 2016 um 0,94°C über dem Mittelwert des 20. Jahrhunderts von 13,9°C. Damit wurde die zuvor schon ermittelte Rekordwärme des Jahres 2015 noch um 0,04°C übertroffen“.
Ein Hundertstel eines Grades ist eine unglaubliche Genauigkeit angesichts des Umstandes, dass die Temperatur auf dem Globus an vielen Tagen Unterschiede bis hundert Grad oder mehr aufweist. Tatsächlich ist das nicht glaubhaft. Die Wahrheit ist, dass diese statistischen Modelle nicht einfach nur ungenau, sondern völlig wertlos sind – und zwar aus folgenden Gründen:
Die Mathematik hinter der Statistik steht auf der Grundlage der Wahrscheinlichkeitstheorie. Folglich ist es eine der absoluten Erfordernisse, dass die Stichprobe zufällig ist. Falls die Stichprobe nicht zufällig ist, kann diese Mathematik nicht angewendet werden.
Tatsächlich sind die in die statistischen Modelle eingehenden Stichproben alles andere als zufällige Stichproben von der Erdoberfläche. Sie zeigen in der Nähe städtischer Gebiete und von Flughäfen in entwickelten Ländern eine starke Drängung. Die Stellen sind nicht ausgewählt nach einem globalen System des Sammelns von Stichproben, und sie sind mit Sicherheit nicht zufällig. Über den Ozeanen ist es sogar noch schlimmer, weil es dort überhaupt keine festen Stationen gibt. In den meisten Gebieten der Erde gab es keine festen, die Temperatur messenden Stationen während des fraglichen Zeitraumes, und das ist immer noch so. Es gibt keine Zufalls-Stichprobe der Temperatur der Erde.
Kurz gesagt, die statistischen Modelle nehmen die verfügbaren Daten und nicht eine Zufalls-Stichprobe der Population. Die Statistik-Theorie des Sammelns von Stichproben legt eindeutig fest, dass Gefälligkeits-Stichproben wie diese nicht herangezogen werden dürfen, um für die gesamte Population eine Statistik abzuschätzen. Aber genau das wird mit der globalen mittleren Temperatur gemacht – bis auf ein hundertstel Grad genau. Das ist einfach Unsinn.
Die statistische Wissenschaft ist eindeutig: eine Gefälligkeits (convenience)-Stichprobe erlaubt keine genaue Schätzung. Hier folgen ein paar Beispiele von verschiedenen Websites bzgl. statistischer Wissenschaft:
A. „Research Methodology” sagt Folgendes:
Nachteile der convenience-Stichprobe:
Hoch anfällig für einen Bias (Vorurteil) bei der Auswahl und für Einflüsse, die sich der Kontrolle der Forscher entziehen.
Hohes Niveau von Stichproben-Fehlern.
Studien auf der Grundlage von convenience-Stichproben haben aus den o. g. Gründen kaum Glaubwürdigkeit.
B. „ThoughtCo.com” sagt Folgendes:
Probleme mit convenience-Stichproben:
Wie die Bezeichnung schon sagt, sind convenience-Stichproben definitiv einfach zu gewinnen. Es gibt praktisch keinerlei Schwierigkeiten bei der Auswahl der Mitglieder der Population für eine convenience-Stichprobe.
Allerdings fordert dieses Fehlen von Mühe einen Preis: convenience-Stichproben sind in der Statistik praktisch wertlos.
C. Bei „Conveniencesampling.net” lesen wir:
Wegen der Fehler bei dieser Art von Gewinnung der Stichproben können Wissenschaftler aus ihren Daten keine konkreten Schlussfolgerungen ziehen.
Also basiert die Globale-Erwärmung-Angst auf globaler Statistik, die keine Glaubwürdigkeit hat, praktisch wertlos ist und keine konkreten Schlussfolgerungen zulässt. Was für ein Durcheinander!
Die alarmistische Klimawissenschaft stolpert über die eigenen Füße bei dem Versuch, eine Periode von zwei Dekaden mit rapider Erwärmung herbeizureden, welche nach den Satellitenbeobachtungen gar nicht existiert. Die Temperaturen werden faked. Mehr muss man dazu nicht sagen.
Link: https://www.cfact.org/2017/05/18/fake-temperatures/
Übersetzt von Chris Frey EIKE
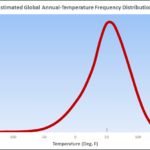
[Bemerkung: Im folgenden Beitrag hat der Autor bei allen Temperaturangaben (in °F) die Zehntel-Ziffer unterstrichen. Ich habe sämtliche Angaben in Grad Celsius umgerechnet, aber auf die Unterstreichung der Zehntel-Ziffern verzichtet. Aus dem Beitrag geht eindeutig hervor, was der Autor damit hervorheben will. Anm. d. Übers.]
Mittelwerte
Mittelwerte sind vielfach nützlich. Ein allgemeiner Nutzen ist es, die Berechnung einer fest vorgegebenen Beschaffenheit genauer und präziser zu machen, wie etwa eine physikalische Dimension. Dies wird erreicht durch die Eingrenzung aller zufälligen Fehler beim Prozess der Messung. Unter geeigneten Umständen wie etwa der Berechnung des Durchmessers eines Balles mittels einer Schublehre können multiple Messungen einen präziseren mittleren Durchmesser ergeben. Grund hierfür ist, dass sich die Zufallsfehler bei der Ablesung auf der Schublehre gegenseitig herausmitteln und die Präzision durch die Standardabweichung gegeben wird, welche invers abhängig ist von der Quadratwurzel der Anzahl der Messungen.
Ein anderer allgemeiner Zweck ist es, die Eigenschaften einer Variablen zu charakterisieren, indem man multiple repräsentative Messungen durchführt und die Häufigkeitsverteilung der Messungen beschreibt. Dies kann graphisch erfolgen oder mittels statistischer Parameter wie Mittelwert, Standardabweichung und Asymmetrie/Wölbung [skewness/kurtosis]. Da jedoch die gemessenen Eigenschaften variieren, wird es problematisch, die Fehler bei den Messungen von der Variabilität der Eigenschaften zu trennen. Folglich erfahren wir mehr darüber, wie die Eigenschaft variiert, als über die Verteilung des zentralen Wertes. Und doch konzentrieren sich Klimatologen auf die arithmetischen Mittel sowie die daraus errechneten Anomalien. Mittelwerte können Informationen verschleiern, sowohl absichtlich als auch unabsichtlich.
Damit im Hinterkopf müssen wir untersuchen, ob zahlreiche Messungen der Temperaturen auf dem Festland, den Ozeanen und der Luft uns wirklich einen präzisen Wert für die „Temperatur“ der Erde vermitteln können.
Die „Temperatur“ der Erde
Der Konvention zufolge ist das Klima üblicherweise definiert als das Mittel meteorologischer Parameter über einen Zeitraum von 30 Jahren. Wie können wir die verfügbaren Temperaturdaten verwenden, welche zum Zwecke der Wetterüberwachung und -vorhersage ermittelt werden, um das Klima zu charakterisieren? Das gegenwärtig angewendete Verfahren ist die Berechnung eines arithmetischen Mittels für eine willkürliche Referenzperiode und dann die Subtraktion tatsächlicher Temperaturmessungen (entweder individuelle Werte oder Mittelwerte) von dieser Referenzperiode, um etwas zu erhalten, was man Anomalie nennt. Was jedoch bedeutet es, alle Temperaturdaten zu sammeln und das Mittel zu berechnen?
Befände sich die Erde im thermodynamischen Gleichgewicht, würde es nur eine Temperatur geben, die zu messen recht einfach wäre. Die Erde hat aber nicht nur eine Temperatur, sondern eine unendliche Vielfalt von Temperaturen. Tatsächlich variiert die Temperatur ununterbrochen horizontal, vertikal und mit der Zeit, was eine unendliche Anzahl von Temperaturen ergibt. Die offensichtliche Rekord-Tiefsttemperatur beträgt -135,8°F [ca. -93,2°C] und die aufgezeichnete Höchsttemperatur 159,3°F [ca. 70,7°C]. Die maximale Bandbreite beträgt also 295,1°F, die geschätzte Standardabweichung etwa 74°F, dem Empirischen Gesetz zufolge. Änderungen von weniger als einem Jahr sind sowohl zufällig als auch saisonal, längere Zeitreihen enthalten periodische Änderungen. Die Frage lautet, ob das Sammeln [von Daten an] einigen tausend Stellen über eine Periode von Jahren uns einen Mittelwert geben kann, welcher einen vertretbaren Wert beim Aufzeigen einer geringen Änderungsrate liefert?
Eines der Probleme ist, dass Wassertemperaturen dazu neigen, geschichtet aufzutreten. Die Wassertemperatur an der Oberfläche neigt dazu, die wärmste Schicht zu sein, darunter nimmt die Temperatur mit der Tiefe ab. Oftmals gibt es eine abrupte Änderung der Temperatur, Thermokline genannt. Außerdem kann aufwallendes Tiefenwasser kaltes Wasser an die Oberfläche bringen, vor allem entlang von Küsten. Daher ist die Lokalisierung und Tiefe der Datenproben entscheidend bei der Berechnung so genannter Meeresoberflächen-Temperaturen (SST). Des Weiteren muss berücksichtigt werden, dass – weil Wasser eine um 2 bis 5 mal höhere spezifische Wärme aufweist als normale Flüssigkeiten und eine vier mal höhere als Luft – es sich viel langsamer erwärmt als das Festland! Es ist unangebracht, SSTs mit Festlandstemperaturen zu mitteln. Das ist ein klassischer Fall eines Vergleiches von Äpfeln und Birnen. Falls jemand Trends der sich ändernden Temperatur erkennen will, können sie auf dem Festland offensichtlicher hervortreten als über den Ozeanen, obwohl Wassertemperaturen dazu neigen, Zufalls-Fluktuationen zu unterdrücken. Es ist vermutlich am besten, SSTs mit einer Skala zu plotten, die vier mal so groß ist wie bei den Festlandstemperaturen und beide in die gleiche Graphik einzutragen zum Vergleich.
Bei Temperaturen auf dem Festland ergibt sich oftmals das ähnlich gelagerte Problem von Temperatur-Inversionen, das heißt, es ist in den bodennahen Luftschichten kälter als in größerer Höhe darüber. Dies ist das Gegenteil dessen, was die Adiabate vorgibt, dass nämlich die Temperatur in der Troposphäre mit der Höhe abzunehmen hat. Aber dies stellt uns vor ein weiteres Problem. Temperaturen werden in Höhen aufgezeichnet, die in einem Bereich von unter dem Meeresspiegel (Death Valley) bis über 3000 Metern Seehöhe liegen. Anders als es die Allgemeine Gasgleichung vorgibt, welche die Eigenschaften eines Gases bei Standard-Temperatur und -Druck festlegt, werden alle Wetter-Temperaturmessungen bei der Mittelung in einen Topf geworfen, um ein arithmetisches Mittel der globalen Temperatur zu erhalten ohne Berücksichtigung der Standard-Drücke. Dies ist wichtig, weil die Allgemeine Gasgleichung vorgibt, dass die Temperatur eines Luftpaketes mit abnehmenden Druck abnimmt, was das Temperaturgefälle steigen lässt.
Historische Aufzeichnungen (vor dem 20.Jahrhundert) sind besonders problematisch, weil Temperaturen nur auf das nächste ganze Grad Fahrenheit abgelesen wurden – von Freiwilligen, die keine professionellen Meteorologen waren. Außerdem war die Technologie von Temperaturmessungen nicht ausgereift, besonders hinsichtlich standardisierter Thermometer.
Klimatologen haben versucht, die oben beschriebenen zusammengewürfelten Faktoren zu umschreiben mit der Überlegung, dass Genauigkeit und damit Präzision verbessert werden kann durch Mittelbildung. Als Grundlage ziehen sie 30-Jahres-Mittel jährlicher Mittel monatlicher Mittel heran, womit sie die Daten glätten und Informationen verlieren! Tatsächlich besagt das ,Gesetz über Große Zahlen‘, dass die Genauigkeit gesammelter Stichproben verbessert werden kann (falls keine systematischen Verzerrungen präsent sind!). Dies gilt besonders für probabilistische Ereignisse wie etwa das Werfen einer Münze. Falls jedoch jährliche Mittelwerte aus monatlichen Mittelwerten abgeleitet werden anstatt aus täglichen Mittelwerten, dann sollten die Monate gewichtet werden der Anzahl der Tage in jenem Monat gemäß. Es ist unklar, ob dies gemacht wird. Allerdings werden selbst tägliche Mittelwerte extrem hohe und tiefe Temperaturen glätten und somit die vorhandene Standardabweichung reduzieren.
Jedoch selbst wenn man die oben beschriebenen Probleme nur vorübergehend ignoriert, gibt es das fundamentale Problem zu versuchen, Lufttemperaturen an der Erdoberfläche präziser und genauer zu erfassen. Anders als der Ball mit im Wesentlichen einem Durchmesser (mit minimaler Exzentrizität) ändert sich die Temperatur an jedem Punkt der Erdoberfläche ständig. Es gibt keine einheitliche Temperatur für irgendeine Stelle zu irgendeinem Zeitpunkt. Und man hat nur eine Gelegenheit, jene vergängliche Temperatur zu messen. Man kann nicht multiple Messungen durchführen, um die Präzision einer bestimmten Messung der Lufttemperatur präziser machen!
Temperatur-Messungen
Höhlen sind dafür bekannt, stabile Temperaturen aufzuweisen. Viele variieren um weniger als ±0,5°F jährlich. Allgemein wird angenommen, dass die Temperatur der Höhle eine mittlere jährliche Lufttemperatur an der Oberfläche reflektieren, jedenfalls an der Stelle, an der sich die Höhle befindet. Während die Lage ein wenig komplexer ist, ist es doch eine gute Approximation erster Ordnung. (Zufälligerweise gibt es einen interessanten Beitrag von Perrier et al. (2005) über einige sehr frühe Arbeiten in Frankreich hinsichtlich Temperaturen im Untergrund. Zur Illustration wollen wir einmal annehmen, dass ein Forscher die Notwendigkeit sieht, die Temperatur einer Höhle während einer bestimmten Jahreszeit zu bestimmen. Der Forscher möchte diese Temperatur mit größerer Präzision ermitteln als es ein durch die Gänge getragenes Thermometer vermag. Der Wert sollte nahe dem nächsten Zehntelgrad Fahrenheit liegen. Diese Situation ist ein ziemlich guter Kandidat für multiple Messungen zur Verbesserung der Präzision, weil es über einen Zeitraum von zwei oder drei Monaten kaum Temperaturänderungen geben dürfte und die Wahrscheinlichkeit hoch ist, dass die gemessenen Werte normalverteilt sind. Die bekannte jährliche Bandbreite gibt an, dass die Standardabweichung unter (50,5 – 49,5)/4 oder etwa 0,3°F liegen sollte. Daher ist die Standardabweichung der jährlichen Temperaturänderung von gleicher Größenordnung wie die Auflösung des Thermometers. Weiter wollen wir annehmen, dass an jedem Tag, wenn die Stelle aufgesucht wird, der Forscher als Erstes und als Letztes die Temperatur abliest. Nach 100 Temperaturmessungen werden die Standardabweichung und der Standardfehler des Mittelwertes berechnet. Unter der Voraussetzung, dass es keine Ausreißer gibt und das alle Messungen um wenige Zehntelgrad um den Mittelwert verteilt sind, ist der Forscher zuversichtlich, dass es gerechtfertigt ist, den Mittelwert bekanntzugeben mit einer signifikanten Zahl mehr als das Thermometer direkt zu messen in der Lage war.
Jetzt wollen wir dies mit der allgemeinen Praxis im Bereich Klimatologie kontrastieren. Klimatologen verwenden meteorologische Temperaturen, die vielleicht von Individuen abgelesen werden mit geringerem Interesse an gewissenhaften Beobachtungen als die einschlägige Forscher haben. Oder Temperaturen wie etwa von den automatisierten ASOS können zum nächsten ganzen Grad Fahrenheit gerundet und zusammen gebracht werden mit Temperaturwerten, die zum nächsten Zehntelgrad Fahrenheit gerundet sind. (Zu allermindest sollten die Einzelwerte invers zu ihrer Präzision gewichtet werden). Weil die Daten eine Mittelung (Glättung) durchlaufen, bevor das 30-Jahre-Referenzmittel berechnet wird, scheint die Datenverteilung zusätzlich weniger verzerrt und mehr normalverteilt, und die berechnete Standardabweichung ist kleiner als sie es bei Verwendung der Rohdaten wäre. Es ist nicht nur die Mitteltemperatur, die sich jährlich ändert. Die Standardabweichung und Verzerrung ändert sich mit Sicherheit ebenfalls, aber dazu werden keine Angaben gemacht. Sind die Änderungen der Standardabweichung und der Verzerrung zufälliger Natur oder gibt es einen Trend? Falls es einen Trend gibt, was ist dafür die Ursache? Was bedeutet das, falls es überhaupt etwas bedeutet? Da sind Informationen, die nicht untersucht und bekannt gegeben werden, obwohl sie Einsichten in die Dynamik des Systems vermitteln können.
Man gewinnt sofort den Eindruck, dass die bekannten höchsten und tiefsten Temperaturen (siehe oben) zeigen, dass die Datensammlung eine Bandbreite bis zu 300°F haben kann, wenngleich auch näher bei 250°F. Wendet man zur Schätzung der Standardabweichung die Empirische Regel an, würde man einen Wert über 70°F dafür vorhersagen. Geht man konservativer vor und zieht man das Tschbycheff’sche Theorem heran und teilt durch 8 anstatt durch 4, ergibt sich immer noch eine Schätzung über 31°F. Außerdem gibt es gute Gründe für die Annahme, dass die Häufigkeitsverteilung der Temperaturen verzerrt ist mit einem langen Schwanz auf der kalten Seite. Im Kern dieses Arguments steht die Offensichtlichkeit, dass Temperaturen unter 50°F unter Null normaler sind als Temperaturen über 150°F, während das bekannt gemachte Mittel der globalen Festlands-Temperaturen nahe 50°F liegt.
Im Folgenden wird gezeigt, wie meiner Ansicht nach die typischen jährlichen Rohdaten aussehen sollten, wenn sie als Häufigkeitsverteilung geplottet werden, wobei man die bekannte Bandbreite, die geschätzte Standardabweichung und das veröffentlichte Mittel berücksichtigt:
Die dicke, rote Linie repräsentiert die typischen Temperaturen eines Jahres, die kurze grüne Säule (in der Skala eingeordnet) repräsentiert die Temperatur in einer Höhle bei obigem Temperatur-Szenario. Ich bin zuversichtlich, dass das Mittel der Höhlentemperatur bis zu einem Hundertstel Grad Fahrenheit präzise ist, aber trotz der gewaltigen Anzahl von Messungen der Temperatur auf der Erde bringe ich Gestalt und Verteilung der globalen Daten längst nicht die gleiche Zuversicht für die globalen Temperaturen auf! Es ist offensichtlich, dass die Verteilung eine erheblich größere Standardabweichung aufweist als die Höhlentemperatur, und die Rationalisierung mittels Teilung der Quadratwurzel der Anzahl kann nicht gerechtfertigt sein, um Zufallsfehler zu eliminieren, wenn der gemessene Parameter niemals zweimal den gleichen Wert aufweist. Die multiplen Schritte der Mittelung der Daten reduziert Extremwerte und die Standardabweichung. Die Frage lautet: „Ist die behauptete Präzision ein Artefakt der Glättung, oder ergibt das Glättungsverfahren einen präziseren Wert?“ Darauf weiß ich keine Antwort. Es ist jedoch mit Sicherheit etwas, das diejenigen beantworten und rechtfertigen sollten, die die Temperatur-Datenbasis erstellen!
Zusammenfassung
Die Theorie der anthropogenen globalen Erwärmung prophezeit, dass man die stärksten Auswirkungen nachts und im Winter sehen wird. Das heißt, der kalte Schwanz in der Kurve der Häufigkeitsverteilung sollte sich verkürzen und die Verteilung symmetrischer werden. Dies würde die berechnete globale Mitteltemperatur zunehmen lassen, selbst wenn sich die Temperaturen im hohen und mittleren Bereich gar nicht ändern. Die Prophezeiungen zukünftiger katastrophaler Hitzewellen basieren auf der unausgesprochenen Hypothese, dass mit der Zunahme des globalen Mittels sich die gesamte Kurve der Häufigkeitsverteilung hin zu höheren Temperaturwerten verschieben würde. Das ist keine gewünschte Hypothese, weil die Differenz zwischen täglichen Höchst- und Tiefsttemperaturen während des 20. Jahrhunderts nicht konstant war. Sie bewegen sich nicht in Stufen, möglicherweise weil es unterschiedliche Faktoren gibt, welche die Höchst- und Tiefstwerte beeinflussen. Tatsächlich waren einige der tiefsten Tiefsttemperaturen in der Gegenwart gemessen worden! In jedem Falle ist eine globale Mitteltemperatur keine gute Maßzahl für das, was mit den globalen Temperaturen passiert. Wir sollten die Trends der täglichen Höchst- und Tiefsttemperaturen in allen Klimazonen betrachten, wie sie durch physikalische Geographen definiert worden sind. Wir sollten auch die Form der Häufigkeits-Verteilungskurven für verschiedene Zeiträume analysieren. Der Versuch, das Verhalten des ,Klimas‘ der Erde mit einer einzelnen Zahl zu charakterisieren, ist keine gute Wissenschaft, ob man nun an Wissenschaft glaubt oder nicht.
Link: https://wattsupwiththat.com/2017/04/23/the-meaning-and-utility-of-averages-as-it-applies-to-climate/
Übersetzt von Chris Frey EIKE
Die Abdeckung mit Klimanachrichten war bereits vor dem Wahljahr über den Peak, aber der vernichtende Zusammenbruch in einem massiven und „jemals heißesten El Nino-Jahr“ sagt viel. Trumps Spott über das Thema war etwas, was die Medien nicht verarbeiten konnten. Es war kein Fall von irgendwelchen Nachrichten sind gute Nachrichten, oder wie immer das Klischee geht. Wenn Trump oder den Bedauernswerten [Wählern von Trump – Hillary Clinton] irgendeine echte Sendezeit gegeben worden wäre, wäre die ganze Rendite suchende Fantasie-Abzocke aus dem Ruder gelaufen.
Der Typ, der Erwärmung kreischte, hatte den Klimawandel verantwortlich gemacht für Dürren, Starkregen, Stürme, Schnee, verlorene Kühe und „falsche“ Wähler. Da bleibt nichts mehr übrig. Jeder Schatten der nahen und fernen Apokalypse ist zu Tote geritten worden und dann nannte Trump ihren Bluff beim Namen und sie liefen weg. Sie hatten jahrelang Spott und Denunziation benutzt, um Kritiker zum Schweigen zu bringen, aber als Trump ihren Spott aufnahm und ihn zurückwarf, hatten sie keine Munition mehr. Sie hatten die Debatte nicht mit Vernunft und Argumentation geführt, sondern durch Spott. Trump verwandte nun ihre Hauptwaffe gegen sie selbst.
Erschienen am 27.03.2017
http://joannenova.com.au/2017/03/climate-media-news-coverage-collapsed-in-the-2009-election-year/
Weitere Einzelheiten von Kate Yoder
Das ist ein dramatischer, 66-prozentiger Rückgang gegenüber der Abdeckung von 2015 der abendlichen und sonntäglichen Nachrichten Sendungen auf ABC, CBS, NBC und Fox, nach einer aktuellen Studie von Media Matters. ABC zum Beispiel, brachte nur sechs Minuten zu Klima Fragen im Jahr 2016.
Dabei können die Netzwerke nicht klagen, dass es einen Mangel an wichtigen Klimageschichten gab. Hurrikane Matthew, der langsame Tod des Großen Barrier Riffs, die rekordverdächtige Hitze, und der Beginn der Pariser Klimaabkommen fanden in 2016 statt.
Interessanterweise scheint das nachlassende Interesse an Klimanachrichten kein Phänomen des Wahljahres zu sein. Im vorangegangenen Wahlzyklus zwischen 2011 und 2012 erhöhte sich die Anzahl der Klimanachrichten um 43 Prozent.
Weitere Einblicke aus der Studie:
Toll zu wissen, dass die Medien in den Nachrichten die wesentlichen Probleme unserer Zeit so ernst nehmen.
Erschienen am 23.März 2017 auf grist.org
Major TV networks spent just 50 minutes on climate change — combined — last year.
Interessant auch über was, bzw. über was nicht berichtet wurde. Hier weitere Einzelheiten aus der aktuellen Studie von Media Matters:
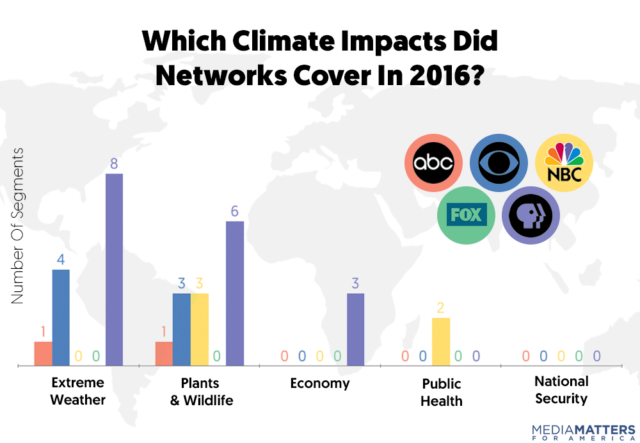
Die Sender brachten keinerlei Nachrichten zur nationalen Sicherheit. Zahlreiche Militär- und Geheimdienste haben über Verbindung des Klimawandels in Bezug auf die nationale Sicherheit alarmiert. Ein Bericht vom September 2016, der vom National Intelligence Council vorbereitet und mit den US-Geheimdiensten koordiniert wurde, erklärte: „Der Klimawandel und seine daraus resultierenden Effekte dürften in den kommenden 20 Jahren weitreichende nationale Sicherheitsherausforderungen für die USA und andere Länder darstellen.“ Und nach Trump’s Wahlsieg, „eine Gruppe von Verteidigungsexperten und ehemaligen Militärführern schickte Trump’s Übergangsteam eine Instruktion, den Klimawandel als eine ernste Bedrohung für die nationale Sicherheit zu betrachten“, berichtete E & E News. Dennoch sind die nationalen Sicherheitsaspekte des Klimawandels in keiner der Nachrichtensendungen in 2016 aufgetreten. [Media Matters, 1/13/17; Scientific American, 11/15/16]
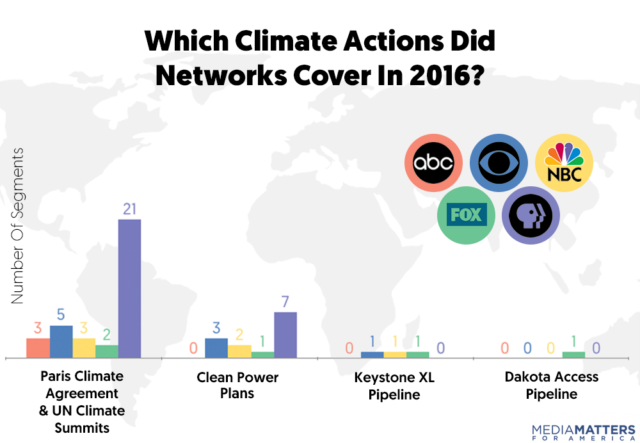
Der Clean Power Plan wurde bei den Sonntagsnachrichten fast vollständig ignoriert und in den nächtlichen News Shows nur spärlich behandelt – und das, obwohl Trump während der Kampagne versprochen hatte, diese Politik zu beseitigen. Der Clean Power Plan schafft die ersten Grenzwerte für die CO2-Verschmutzung durch Kraftwerke und dient als Dreh- und Angelpunkt des Programms von Präsident Obama, um die Emissionsminderungsverpflichtung der Nation nach dem Pariser Abkommen zu erfüllen.
* * *
Übersetzt durch Andreas Demmig
Abbildung oben: Beispiel von acht Zufallsbewegungen in einer Dimension mit dem Startpunkt 0. Der Plot zeigt die gegenwärtige Position auf der Linie (vertikale Achse) im Verhältnis zu den Zeitschritten (horizontale Achse). Bild: Wikimedia
Als Erwiderung darauf sponsere ich einen Wettbewerb: Der Preis beträgt 100.000 Dollar. Im Wesentlichen wird jedem der Preis zuerkannt, der mittels statistischer Analyse zeigen kann, dass die Zunahme der globalen Temperatur möglicherweise nicht der zufälligen natürlichen Variation geschuldet ist.
Heute schreibt Doug J. Keenan:
Im November 2015 habe ich einen Wettbewerb ausgeschrieben mit 100.000 Dollar Preisgeld: um Trends in Zeitreihen ausfindig zu machen – Zeitreihen ähnlich den globalen Temperatur-Zeitreihen. Darüber gibt es einen Blogbeitrag: „Finde den Trend: 100.000 Dollar für jeden, der zeigen kann, dass Klima- und Temperaturdaten nicht Zufall sind“ (hier).
Der Wettbewerb ist jetzt beendet. Die Lösung und einige Bemerkungen wurden gepostet. In Kürze: Niemand kam auch nur annähernd dem Gewinn nahe. Unter den Teilnehmern am Wettbewerb waren sehr bekannte Forscher.
Viele Leute haben behauptet, dass gezeigt werden kann, dass die Zunahme der globalen Temperaturen (seit 1880) mehr als nur zufälliges Rauschen ist. Derartige Behauptungen sind falsch, wie der Wettbewerb effektiv gezeigt hat. Aus statistischer Perspektive kann die Temperaturzunahme sehr wohl der zufälligen natürlichen Variation geschuldet sein.
Von seinem Blog: http://www.informath.org/Contest1000.htm
18. August 2016
Eine Studie von Lovejoy et al. wurde in den Geophysical Research Letters veröffentlicht. In der Studie geht es um den Wettbewerb.
Die Studie beruht auf der Beteuerung, dass im Wettbewerb „ein stochastisches Modell mit einigem Realismus zum Einsatz kam“; danach behauptet die Studie, dass es dem Wettbewerbs-Modell an Realismus fehlt. Tatsächlich stelle ich eine solche Behauptung auch gar nicht auf. Mehr noch, meine Kritik an den statistischen Analysen des IPCC (siehe oben) lautet, dass niemand ein Modell mit angemessenem Realismus wählen kann. Folglich ist die Basis dieser Studie hinfällig. Genau das habe ich dem Leitautor der Studie Shaun Lovejoy auch gesagt, aber Lovejoy veröffentlichte die Studie trotzdem.
Bei einer statistischen Analyse besteht der erste Schritt darin, ein Modell des Verfahrens zu wählen, welches die Daten erzeugte. Das IPCC hat tatsächlich ein Modell gewählt. Ich habe lediglich behauptet, dass das im Wettbewerb verwendete Modell realistischer daherkommt als das vom IPCC gewählte Modell. Falls also das Wettbewerbs-Modell unrealistisch ist (was es ist), dann ist das IPCC-Modell sogar noch unrealistischer. Folglich sollte das IPCC-Modell nie herangezogen werden. Ergo sind die statistischen Analysen im IPCC-Bericht unhaltbar, was auch die Kritik ausmacht.
Zur Illustration Folgendes: Lovejoy et al. behaupten, dass das Wettbewerbs-Modell eine typische Temperaturänderung von 4°C alle 6400 Jahre enthält – was zu viel ist, um realistisch zu sein. Und doch enthält das IPCC-Modell eine Temperaturänderung von etwa 41°C alle 6400 Jahre. (Zur Bestätigung siehe Abschnitt 8 der Kritik und die Tatsache, dass 0.85×6400/133 = 41 ist). Folglich ist das IPCC-Modell weitaus unrealistischer als das Wettbewerbs-Modell, jedenfalls dem von Lovejoy et al. befürworteten Test zufolge. Würde also der Test von Lovejoy et al.übernommen, wären die statistischen Analysen des IPCC unhaltbar.
Dazu wird man in Zukunft wohl noch mehr zu sagen haben.
1. Dezember 2016
Betrachtet man die mit dem schwachen PRNG vor dem 22. November 2015 erzeugten 1000 Reihen, sind ANSWER, das PROGRAM (Maple worksheet) und die Function zum Erstellen des Files Answers1000.txt jetzt verfügbar (with the random seed being the seventh perfect number minus one) [?]
Cowpertwait P.S.P., Metcalfe A.V. (2009), Introductory Time Series with R(Springer). [The analysis of Southern Hemisphere temperatures is in §7.4.6.]
Shumway R.H., Stoffer D.S. (2011), Time Series Analysis and Its Applications(Springer). (Im Example 2.5 werden die jährlichen Änderungen der globalen Temperatur in Betracht gezogen, und es wird darin argumentiert, dass das Mittel jener Änderungen sich nicht signifikant von Null unterscheidet. In Problem 5.3 wird das näher ausgeführt).
Link: https://wattsupwiththat.com/2016/12/08/global-warming-fails-the-random-natural-variation-contest/
Übersetzt von Chris Frey EIKE
Achtung: Diese News wurde ergänzt, (s. u.)
Um mir selbst ein Bild zu machen, und da wir gewohnt sind, uns auf Beobachtungen zu verlassen, statt auf Prognosen, habe ich vor etwa einem Jahr die in Wetterzentrale.de gespeicherten und um 1700 beginnenden Temperaturmessungen ausgewertet. Die Erarbeitung von ca. 300 Temperaturganglinien hat viele Kenntnisse aus meiner jahrzehntelangen Hydrogeologen-Zeit bestätigt.
Auf der Grundlage meiner Beschäftigung mit Temperaturganglinien möchte ich zu der NASA-Grafik, die Sie in Ihrem Artikel NASA: 2009 auf Rang 2 vom 18.1.2010, kommentiert haben, anmerken, dass man diese Temperaturganglinie in Analogie zu anderen Klimaentwicklungen anders interpretieren sollte, nämlich so, wie ich sie zusätzlich eingezeichnet habe. Sie stimmt dann in ihrer Aussage auch recht gut mit den Ganglinien anderer Institute überein. Selbst wenn 2009 das zweitwärmste Jahr gewesen sein sollte – man wird ja unsicher, welchen Daten man noch trauen kann –, ist daraus nicht zu folgern, dass die Erwärmung weiter geht. Warten wir doch ein paar Jahre ab!
Glück auf! F.-K. Ewert EIKE
25.23.10
Sehr geehrte Kommentatoren,
Das Originalzitat von Herrn Rahmstorf finden Sie unter dem von mir angegebenen Link NASA: 2009 auf Rang 2.
Sie haben um Beispiele für analoge Klimaentwicklungen gebeten. Ich habe bei meiner Auswertung der Temperaturdaten aus www.wetterzentrale.de dafür viele Beispiele gefunden. Eines füge ich bei; alle anderen werden im Rahmen einer umfassenden Ausarbeitung demnächst hier zu sehen sein.
Man kann in die Temperaturganglinie die Trendlinie als gerade Linie einzeichnen, weil Einzelheiten unberücksichtigt bleiben sollen – oder müssen. Man kann aber auch die Einzelabschnitte betrachten, um damit – beispielsweise – eine städtebauliche Entwicklung zum Ausdruck zu bringen, die man natürlich kennen muss. Letzteres macht mehr Arbeit, lohnt sich aber, denn man entdeckt dabei, wie gut die Temperaturganglinie die Stadtentwicklung reflektiert. Die Station New York, Central Park, zeigt das nahezu perfekt:
Das Verfahren der Einzelabschnittanalyse funktioniert gut; deshalb habe ich es angewendet, und zwar nicht nur in diesem Fall.
Apropos „…– man wird ja unsicher, welchen Daten man noch trauen kann – …..“: Die Zuverlässigkeit der NASA-Daten habe ich damit nicht bezweifelt. Wenn man allerdings Herrn Rahmstorfs Interpretation der NASA-Kurve folgt – die Erwärmung setzt sich fort – dann widerspricht sie der Hadley-Kurve, die eine Abkühlung anzeigt. Den Widerspruch kann man auf zweierlei Weise auflösen:
Glück auf! F.-K. Ewert