Dieses Muster lässt sich an allen Grafiken der täglich neu bestätigten Infektionen sowohl in allen Bundesländern Deutschlands als auch in den Kantonen der Schweiz, und Staaten Europas bereits seit 6 Wochen so ablesen (Grafik 1 und Grafik 2).
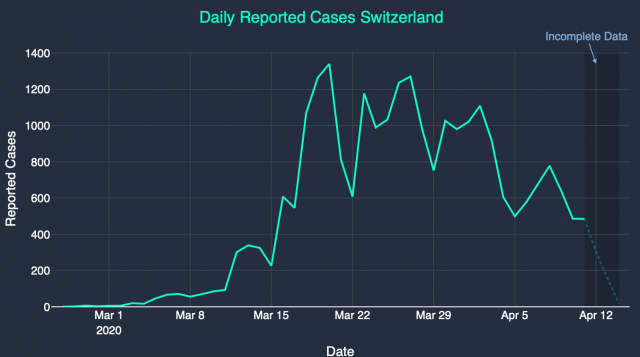
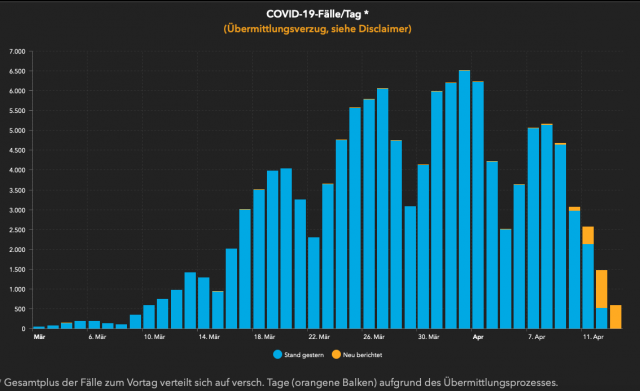
Dass das Virus am Wochenende nicht arbeitet, ist klar, da haben die meisten Testlabore geschlossen – aber warum Freitag?
Wie die meisten Erkältungs- und Grippeviren auch, scheint sich das Corona-Virus einen 7-Tages-Rhythmus angeeignet zu haben. Das erklärt sich aus den Lebensgewohnheiten des menschlichen Wirtes. Wer sich am Wochenende beim Feiern oder anderen sozialen Anlässen ansteckt, der arbeitet die Werkwoche noch durch, fühlt sich dann gegen Ende der Woche bereits angeschlagen, aber geht noch mal den ersehnten Freizeitaktivitäten mit intensivem sozialen Kontakt am nächsten Wochenende nach. Dort steckt diese Person gerade noch alle anderen an, bevor dann in der zweiten Woche das Bett gehütet wird. Virenmutationen, die besonders schnell zu Symptomen führen oder den Wirt mit heftig einsetzenden Schmerzen früher ins Bett scheuchen, verpassen die Gelegenheit, sich jeweils am nächsten Wochenende beim Feiern verbreiten zu können und verschwinden folglich. So will es die Evolution.
Dass das aktuelle Corona-Virus denselben 7-Tages-Rhythmus hat, in der Fachsprache Serienintervall genannt, wurde schon früh in Asien festgestellt und bestätigt sich in Europa erneut. Der weitere Verlauf muss wohl so sein, dass der betroffene Patient sich dann am Dienstag nach dem zweiten Wochenende – mit dann bereits seit mehreren Tagen anhaltendem Fieber – entscheidet, einen Test zu besorgen, diesen am Donnerstag durchführt, und dann die Ergebnisse am Freitag registriert werden. So kommt die Statistik zu ihrem rhythmisch wiederkehrenden Erscheinungsbild, und so ergeben sich 14 Tage von Infektion bis Meldung. Natürlich gibt es Abweichungen von dieser Norm, aber die Zahlen zeigen, dass dies im großen Durchschnitt der Fall ist.
Das Virus ist reisefaul
Diese regelmäßigen Zyklen des Corona-Virus erlauben es, durch statistische Analyse nachzuvollziehen, welche Kohorte sich wann angesteckt hat. Zum Beispiel die Kohorte mit 1.104 Neuregistrierten, die am Freitag, dem 27. März, in Nordrhein-Westfalen (NRW) gemeldet wurde, hat sich dementsprechend zwei Wochen zuvor, am Freitag, dem 13. März, angesteckt. Und zwar bei der vorhergehenden Kohorte, die am 20. März mit 839 Personen in NRW als infiziert gemeldet wurde. Diese 839 Personen haben also 1.104 Personen angesteckt, was eine Ansteckungsrate – oder auch Reproduktionsrate genannt – von 1,3 ergibt, oder R 1,3 (= 1104/839). Die Infektionen müssen weitgehend in NRW stattgefunden haben, weil die starken regionalen Unterschiede zeigen, dass das Virus reisefaul ist – es hat sich von NRW aus nicht in seine Nachbarländer verbreitet. Diese Reisefaulheit zeigt sich auch darin, dass große Verkehrsdrehkreuze wie Frankfurt oder Zürich nur schwach infiziert sind. Das Benutzen von Massenverkehrsmitteln ist nicht infektionsgefährlich.
Das wichtige an dieser R-Berechnung ist, dass jener 13. März als Tag der Ansteckung, der letzte Freitag vor den Ausgangsbeschränkungen und Kontaktsperren war, die am 16. März begannen. Die Reproduktionsrate lag also schon VOR den drakonischen Lockdown-Maßnahmen des 16. März bei höchstens 1,3. Man braucht nicht promovierter Epidemiologe zu sein, um diese Zahl zu ermitteln. Sie erschließt sich frei zugänglich aus den Daten des Robert-Koch-Institutes (RKI) mit einfacher Grundschulmathematik. Meine Berechnungen sind hier zu finden.
Aber die Zahl kann noch weiter nach unten korrigiert werden. Denn diejenigen Erkrankten, die versucht hatten, sich am Donnerstag, dem 19. März, testen zu lassen, hatten es schwieriger, an einen Test zu kommen. Diese waren noch nicht so leicht verfügbar wie eine Woche später, am 26. März. Das bedeutet, es wurden relativ weniger Erkrankte getestet, und die Dunkelziffer der Kohorte der am 20. März Neuregistrierten war höher als die der Kohorte vom 27. März. Über diese Dunkelziffer gibt es keine gesicherten Angaben, und vermutlich wird sie nie mehr eindeutig rekonstruierbar sein. Aus den Berichten des RKI über den Anteil der positiv Getesteten an allen Tests kann eine konservative Schätzung gewonnen werden, dass die Dunkelziffer in der 12. Kalenderwoche (KW 16.–22. März) 32 Prozent höher lag als in der 14. KW (ab 30. März), und respektive 53 Prozent in der 11. KW (9.–15. März).
Der Lockdown hatte keinen messbaren Effekt
Mit dieser Korrektur ergibt sich, dass die Reproduktionsrate R in NRW sogar schon am 9. März unter 1,0 lag und folglich die Epidemie am Abklingen war. Dieselbe Rechnung für mehrere Bundesländer und alle Tageskohorten zeigt, wie das R bereits um den 10. März herum in NRW, Rheinland Pfalz, Hessen und Hamburg auf den Wert 1,0 gefallen war. In Berlin, Niedersachsen, Baden-Württemberg und Bayern dagegen wurde der Wert 1,0 erst um den 20. März herum erreicht, etwa 10 Tage später. Dieser Unterschied ist von erheblicher Bedeutung. Er zeigt, wie die ersteren vier Bundesländer schon 6 Tage VORdem Lockdown ein R von 1,0 erreicht hatten, und die letzteren vier Bundesländer erst 4 Tage NACH dem Lockdown – aber in allen Fällen mit demselben Verlauf.
Das RKI kommt zu einem ähnlichen Ergebnis wie in meinen Berechnungen. Am 9. April veröffentlichte das RKI seine Erkenntnis, dass sich das R deutschlandweit um den 22. März herum bei 1,0 einpendelte, allerdings ohne seine Zahlen um den erschwerten Testzugang zu kalibrieren (Siehe hier). Mit Kalibrierung würde die RKI-Rechnung im deutschen Mittel um den 15. März herum bei 1,0 liegen, wie bei mir auch. Das RKI unterschlägt jedoch die entscheidende Information, dass es zwischen den einzelnen Bundesländern einen zeitlichen Verzug im Verlauf von bis zu 10 Tagen gibt.
Folglich hatte der Lockdown am 16. März keinen statistisch messbaren Effekt auf die Reproduktionsrate (R) des Virus. In den Wissenschaften nennt sich diese Situation ein „natürliches Experiment“. Wenn die Verläufe von zwei Gruppen identisch miteinander sind, nur zeitlich verzögert, dann lässt sich schlussfolgern, dass ein dazwischen liegendes Ereignis keine Auswirkung hatte. In diesem Fall waren es die Maßnahmen des Lockdown am 16. März, die keine statistisch erkennbare Wirkung auf das Infektionsgeschehen ausüben konnten.
Max-Planck-Gesellschaft schreibt Gefälligkeitsgutachten
Am 8. April veröffentlichte das Max-Planck-Gesellschaft (MPG) Institut für Dynamik und Selbstorganisation in Göttingen ein genau gegenteiliges und in der Presse vielzitiertes Ergebnis: „Die Kontaktsperre bringt die Wende“. „Wir sehen eine klare Wirkung der Kontaktsperre vom 22. März, und natürlich den Beitrag von jeder einzelnen Person“. Die Forscher um Frau Dr. Viola Priesemann müssen für diese Erkenntnis hellseherische Fähigkeiten gehabt haben, denn per 7. April, dem Zeitpunkt ihrer Datenerhebung, war eine solche Erkenntnis aus mathematischen Gründen noch unmöglich. Zudem, für eine Schlüsselvariable in ihren Berechnungen, dass 10 Tage von Infektion bis Meldung vergehen, liefern die Forscher weder eine Herleitung noch eine Quelle und ignorieren damit die auf den ersten Blick erkennbare 14-tägige Rhythmik des Virus.
Vor allem aber haben die Forscher nur den gesamtdeutschen Infektionsverlauf herangezogen und damit die ebenfalls auf einen Blick erkennbaren riesigen Unterschiede pro Bundesland ignoriert. Internationale Vergleiche wurden auch nicht angestellt. Das Zitat, dass der Beitrag jeder einzelnen Person sich in den Zahlen zeige, was grober Unfug ist, entlarvt die Max-Planck-Gesellschaft-Studie endgültig als ein Gefälligkeitsgutachten, anstatt seriöse Wissenschaft zu sein. Solche elementaren handwerklichen Fehler in der Analyse verhelfen vielleicht zu populären Zitaten in der Presse, aber schaden dem Ansehen der Wissenschaften.
Epidemiologen sehen eine Epidemie als weitgehend bewältigt an, wenn das R dauerhaft auf einen Wert von unter 1,0 sinkt, denn ab dann wird jede Kohorte mit jedem Zyklus kleiner, und nach vielen weiteren Zyklen gibt es dann keine Ansteckungen mehr. Mit einem Wert von 1,0 gibt es mindestens kein exponentielles Wachstum mehr und daher auch keine Gefahr mehr, dass das Gesundheitssystem mit einer plötzlichen Patientenwelle überrollt wird. Diese Gefahr bestand, wie die Zahlen jetzt zeigen, bereits seit dem 10. März, also fast eine Woche VOR dem Lockdown am 16. März nicht mehr. Sofern sie ihrer Zahlen mächtig sind, müssten sowohl das RKI wie auch die MPG das seit dem 9. April wissen. Warum wird diese Erkenntnis nicht veröffentlicht? Wollen sie nicht, oder können sie nicht?
Ergebnis wird die schwerste Wirtschaftskrise der Moderne sein
Zu dem Zeitpunkt des 16. März konnten die Entscheidungsträger das alles noch nicht wissen. Man weiß immer erst circa drei Wochen nach dem Infektionsgeschehen, was vor drei Wochen der Status war. Es sei denn, die Behörden hätten schon am 28. Februar mit repräsentativen Zufallsstudien begonnen, als Deutschland schon die zweithöchste Zahl der bestätigten Infektionen in Europa nach Italien hatte. Dann wäre auch das aktuelle Infektionsgeschehen schneller bekannt gewesen. Hätte, hätte Fahrradkette, diese Studien wurden nicht gemacht, und so blieb keine andere Wahl, als am 16. März das Funktionieren der Gesellschaft abzuschalten. Das Ergebnis dieses Lockdowns wird die nun schwerste Wirtschaftskrise seit dem zweiten Weltkrieg sein – ein teures Versäumnis, nicht ein paar Testbatterien bereits im Februar gestartet zu haben.
Immerhin, mittlerweile sind diese drei Wochen seit dem 16. März vergangen – jetzt sind Zahlen für alle ersichtlich, erkenntlich und verständlich verfügbar. Und die Zahlen sprechen eine eindeutige Sprache: Die Ausgangsbeschränkungen und Kontaktsperren des Lockdowns sind nahezu wirkungslos. Die Neuinfektionsraten waren schon vorher ganz von alleine gesunken, ohne dass es den Lockdown des 16. März gebraucht hätte. Zudem liegt auch die Vermutung nahe, dass der Lockdown nicht einmal zur weiteren Reduktion der Reproduktionsrate beigetragen hat. Das R liegt in Deutschland in der zweiten Aprilwoche, bei etwa 0,7. Das wäre wahrscheinlich genauso von alleine passiert wie das Sinken auf 1,0 bereits in der ersten Märzhälfte in NRW. Italien befindet sich bereits in der sechsten Woche eines noch rabiateren Lockdowns der Gesellschaft, und trotzdem ist das R an Ostern immer noch bei 0,8, höher als in Deutschland. Die Schweiz, die ein etwas lockeres Regime als Deutschland fährt, verbucht ein R von 0,6 und die ebenfalls etwas lockeren Niederlande wiederum ein R von 1,0. Offensichtlich sind es andere Faktoren als ein Lockdown, die zu einer niedrigeren Reproduktionsrate führen.
Covid-19 ist äußerst gefährlich
Damit soll auf keinen Fall diese Krankheit verharmlost werden. Ganz im Gegenteil, Covid-19 ist äußerst gefährlich. Am 9. April wurden die ersten Zwischenergebnisse der Heinsberg-Studie von Professor Hendrik Streeck der Universität Bonn vorgestellt. Dort zeigt sich zum ersten Mal repräsentativ, dass die Sterberate unter den Infizierten zwischen 0,29 Prozent und 0,37 Prozent liegt. Das ist drei bis viermal höher als bei einer saisonalen Grippe und doppelt so hoch wie bei einer schweren Grippe. Außerdem ist die Verbreitungsrate sehr viel höher als bei einer Grippe. Es scheint keinerlei Immunität in der Bevölkerung gegen Covid-19 zu geben. Rechnet man diese Werte auf die Bevölkerung hoch, dann würde es im Infektionsverlauf zu vielleicht 200.000 Todesfällen in Deutschland aufgrund von Covid-19 kommen, zehnmal mehr als bei einer saisonalen Grippeepidemie. Das ist eine unakzeptabel hohe Zahl.
Wenn die Maßnahmen des Lockdown ganz oder nahezu wirkungslos sind, dann sind dringend andere Lösungen gefragt, die dieser Krankheit den Schrecken nehmen. Ein Teil der Lösung werden hoffentlich bald Medikamente sein, für die es bereits vielversprechende Kandidaten gibt, und die jetzt schon bei schweren Verläufen eingesetzt werden dürfen. Die sich in Arbeit befindliche Contact Tracing App dürfte ein bedeutender Teil der Lösung sein. Unkompliziert und ständig verfügbare Tests sind unabdingbar, damit Infektionen schnell aufgespürt werden können. Singapur hat die Epidemie lange mit Contact Tracing unter Kontrolle gehalten, aber versäumt, sein verarmtes Heer an ausländischen Dienstleistern zu testen. Genau dort kam es nun zum Ausbruch.
Eine weitere Erkenntnis aus Taiwan ist die höchst transparente und umfängliche Information über das Infektionsgeschehen an die Öffentlichkeit mit bedeutungsvollen Zahlen sowie das konsequente Ausrüsten von exponierten Berufsgruppen mit Schutzmaterial. Taiwans Bürger wurden aufgerufen, auf ihre gewohnten Masken und Desinfektionsmittel zu verzichten (!), damit diese Materialien für die wichtigen Berufsgruppen zur Verfügung stehen. In Summe könnten diese Elemente mit Sicherheit verhindern, dass das Infektionsgeschehen außer Kontrolle gerät, und sie könnten auch fast sicher verhindern, dass die Risikogruppen infiziert werden, ohne sie aus der Gesellschaft zu verbannen. Warum wird fast nicht über Taiwan berichtet?
Wenn es nicht die Maßnahmen vom 16. März waren, die die Infektionswelle abschwächten, was war es dann? Es war wohl das Ende der Karnevalsaison sowohl am Rhein wie in den Alpen. Aus dieser Erkenntnis leitet sich auch ab, welche Maßnahmen bestehen bleiben müssen, bis es entweder Herdenimmunität oder einen zuverlässigen und breit verfügbaren Impfstoff gibt, was beides erst in 2021 erfolgen wird. Bis dahin wird es keine Sportveranstaltungen mit Zuschauern geben können, keine Musikfestivals, keine Oktoberfeste und keine Bars und Clubs. Es wird keine Veranstaltungen geben können, bei der Menschen wild singen, grölen und brüllen. Auch das Apres Ski wird in der nächsten Wintersaison ausfallen. Das sind zwar auch Einschränkungen, aber vergleichsweise harmlos zu den Schäden, die der Gesellschaft mit dem aktuellen Lockdownpaket zugefügt werden, die zudem auch noch wirkungslos zu sein scheinen.
Der rheinische Karneval war der erste Brandbeschleuniger
Die Sterberaten aus Heinsberg lassen die Vermutung zu, dass es um den 25. März herum etwa 600.000 bis dahin Erkrankte in Deutschland gegeben hat, die sich folglich bis etwa eine Woche zuvor – also bis zum 18. März – infiziert haben, mit einer Dunkelziffer von etwa Faktor 20 der offiziellen Fallzahlen. Das ist dieselbe Menge an Erkrankten, die ich vor zwei Wochen bereits aus isländischen und japanischen Quellen in meinem Beitrag auf der Achse des Guten für den Stand vom 25. Märzermittelt hatte.
Vermutlich kann das gesamte Infektionsgeschehen in Deutschland grob wie folgt zusammengefasst werden: Angenommen, die Reproduktionszahlen im Karneval lagen im Durchschnitt bei 14, das heißt ein Infizierter steckte 14 weitere Personen innerhalb einer Woche an. Mit einem R von 14 benötigte es in der Woche vor Karneval am 9. Februar gerade einmal 100 infektiöse Personen entlang der NRW Karnevalshochburgen, die sich in der vielen Feierei und Vorbereiterei frei bewegten, ohne zu wissen, dass sie krank waren. Dass es diese 100 Personen gab, ist leicht vorstellbar. Alleine nur der Lufthansa Konzern beförderte im Januar noch fast 100,000 Personen aus China nach Deutschland. Nur eine einzige davon führte zu 16 bekannten Erkrankten in dem Webastoausbruch in Bayern. Nur sieben weitere unerkannte webastoähnliche Situationen in NRW hätten gereicht für die Starterglut für das Karnevalsfeuer ab Mitte Februar.
Die 100 Personen hätten folglich in der ersten Karnevalwoche bis zum 16. Februar 1.400 (= 100×14) weitere Personen angesteckt. Die berühmte Gangelter Karnevalssitzung im Landkreis Heinsberg fand zum Beispiel am 15. Februar statt. In der zweiten Karnevalswoche vom 17. bis 24.2. steckten diese 1.400, weitere 19.600 an (= 1400 x 14). Die meisten dieser 19.600 hätten auch wieder nicht gemerkt, dass sie krank waren. Viele weitere hätten geglaubt, der anstrengende Karneval hätte ihnen eine schwere Erkältung beschert. Etwa 500 wurden so krank, dass sie innerhalb der nächsten zwei Wochen bis zum 8. März ihren Weg zu einem Corona Test fanden und dort positiv getestet wurden. Es ist bekannt, dass fast die Hälfte aller positiven Tests in Deutschland bis zum 8. März aus NRW kamen.
Die andere Hälfte der positiven Tests in Deutschland würde dann weitere 20.000 Personen bedeuten, die sich irgendwo anders bis zum 23. Februar infizierten. Sie waren wohl über das ganze Land verteilt in kleineren Infektionsketten, jedoch mit einem dicken Schwerpunkt unter solchen Deutschen, die in Skigebieten urlaubten. Dort brach im Apres Ski die zweite Welle los. Ab dem 24. Februar, der Hochsaison in den Alpen, stehen erste echte Daten für das R zur Verfügung. Unter den Süddeutschen wütete sich das Virus durch die Apres Ski Clubs mit einem R von 5, jeder Infizierte steckte dort fünf weitere an. Währenddessen wurde es bereits ruhig in NRW, das R sank dort bis zum 9. März auf 0,9, und am 10. März folgten Rheinland Pfalz, Hessen und Hamburg ebenfalls auf 1,0. Weil in Bayern und Baden-Württemberg die Skiparty noch weiter lief, sank das R dort erst um den 20. März herum auf 1,0.
Im deutschen Durchschnitt bedeutet das, dass die 40.000 Erkrankten vom 23. Februar mit einem R von 2,5 weitere 100.000 Personen bis zum 1. März infizierten, und diese mit einem R von 2 noch mal 200.000 Personen bis zum 8. März, und schließlich mit einem R von 1,3 folgten 260.000 Personen bis zum 15. März, dem Tag der Entscheidung des Lockdowns. Alle diese Personen inkubierten Covid-19, wurden mehr oder minder krank, und etwa jeder Zwanzigste ließ sich in der Woche zwischen dem 23. und 27. März testen. 34.000 insgesamt Infizierte wurden bis zu dieser Woche offiziell gemeldet. Tatsächlich waren aber bis zu diesem Zeitpunkt alles in allem etwa 600.000 erkrankt, wie die Summe der obigen Zahlen aussagt (= 40+100+200+260). Einige von ihnen erkrankten so schwer, dass sie ins Krankenhaus mussten und dort im Durchschnitt nach zwei Wochen verstarben. Von den bis zum 25. März 600.000 Erkrankten sind 0,37 Prozent gestorben, wie die Heinsberg Studie vorgibt – das ergeben dann die 2.200 Sterbefälle, die das RKI bis inklusive dem 8. April gemeldet hat. Auf diese Weise lässt sich aus der Heinsberg Sterberate grob hochrechnen, wie hoch die wahre Infektionszahl in Deutschland war.
Die teuerste Party der Weltgeschichte
Das ist die ungefähre Geschichte in Deutschland. Es gibt Nebengeschichten, zum Beispiel die Posaunenchöre im Kreis Hohenlohe und das Starkbierfest in Mitterteich (Kreis Tirschenreuth), verschiedene Parteitage und die Kommunalwahl in Bayern am 15. März, die sich auch in den Zahlen zeigt. Aber die beiden wesentlichen Brandbeschleuniger waren der rheinische Karneval und dann die alpinen Apres Ski Clubs. Andere Länder haben andere Geschichten zu erzählen. In Norditalien spielten mit Sicherheit die unzähligen Dienstleistungsmitarbeiter eine wichtige Rolle, ohne die in den Alpen keine Bar betrieben werden kann. Im Winter bedienen sie die Skigebiete und im Sommer die Strände. Zuhause gibt es keine gute Arbeit, deswegen sind sie auf Wanderschaft. Aber Nonna und Nonno (italienisch für Großeltern) werden regelmäßig besucht, nicht zuletzt, weil man aufgrund der Wohnungsnot häufig gemeinsam lebt. In Italien haben die Generationen fünfmal häufigeren Kontakt miteinander als in Deutschland. Dieser starke Familienzusammenhalt hat sich in diesem Fall als Fluch erwiesen.
Im spanischen Verlauf lassen sich die Massendemonstrationen zum Weltfrauentag am 8. März leicht ablesen und in Frankreich noch die Kommunalwahl vom 15. März. Dass Großbritannien bis zum 25. März praktisch gar keine Maßnahmen durchführte und vor allem nicht die Pubs geschlossen hatte, beschert Ihnen ein R von 1,2 sogar noch an Ostern. Auch Schweden hat noch immer ein R von 1,3 im April, weil es lange zögerte, große Veranstaltungen abzusagen und die Bars und Clubs zu schließen. Aber Schweden feierte kein Karneval und hat dadurch seine Zahlen nicht im Februar schon so weit in die Höhe getrieben. Daher wirkt das R dort nur auf eine kleinere Anzahl von Personen. Die Untersuchung der Virenmutationen zeigt, dass die amerikanische Westküste sich direkt in China angesteckt hat, aber die amerikanische Ostküste – insbesondere New York – hat sich in Europa angesteckt. Die Zahlen erzählen viele Geschichten, und viele sind weder gezählt noch erzählt.
Wahrscheinlich war der NRW-Karneval das allererste große europäische Infektionszentrum, sozusagen das Ereignis 0, in dem es zahlenmäßig explodierte, und erst darauf folgte die große Welle in den Alpen, von wo es in die ganze Welt getragen wurde. Hätte der Karneval am 13. Februar abgesagt werden können? Mit der Faktenlage, die damals existierte, hätte die Bevölkerung das nicht akzeptiert. Hätten die Behörden, ähnlich wie in Taiwan, genau hingeschaut, was in Wuhan passiert, dann hätten sie es wissen können und hätten der Bevölkerung erklären können, warum der Karneval dieses Mal ausfallen muss. Stattdessen wiegte sich das deutsche Gesundheitssystem in einem falschen Überlegenheitsgefühl und vergeudete wertvolle Zeit der Vorbereitung. So wurde der Karneval 2020 zur teuersten Party der Weltgeschichte.
Der Beitrag erschien zuerst bei ACHGUT hier
Weiterführende Literatur z.B. dieses Thesenpapier zur Pandemie durch SARS-CoV-2/Covid-19 vom 5.4.20 erschienen bei SPRINGER nature
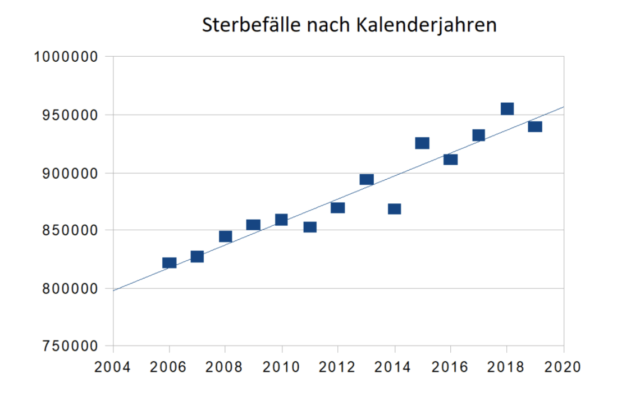
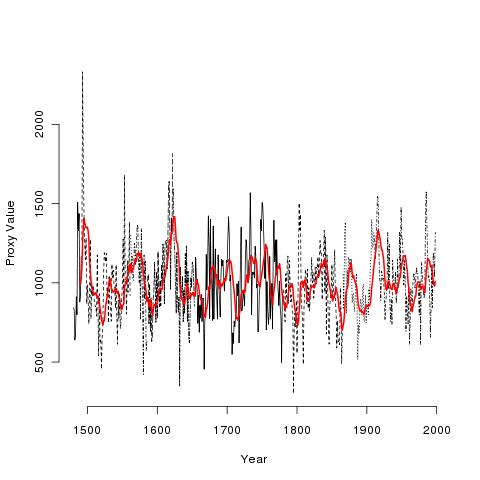 Die verschiedenen schwarzen Linien sind die tatsächlichen Daten! Die rote Linie ist ein geglätteter 10-Jahres-Mittelwert! Ich nenne die schwarzen Daten die realen Daten, und die geglätteten Daten die fiktiven Daten. Mann hat einen „Tiefpassfilter“ verwendet, der sich vom laufenden Mittelwert unterscheidet, um seine fiktiven Daten zu erzeugen, aber eine Glättung ist eine Glättung, und was ich jetzt sage, ändert sich kein bisschen, je nachdem, welche Glättung man verwendet.
Die verschiedenen schwarzen Linien sind die tatsächlichen Daten! Die rote Linie ist ein geglätteter 10-Jahres-Mittelwert! Ich nenne die schwarzen Daten die realen Daten, und die geglätteten Daten die fiktiven Daten. Mann hat einen „Tiefpassfilter“ verwendet, der sich vom laufenden Mittelwert unterscheidet, um seine fiktiven Daten zu erzeugen, aber eine Glättung ist eine Glättung, und was ich jetzt sage, ändert sich kein bisschen, je nachdem, welche Glättung man verwendet.












{kind=link}
{kind=link}
{kind=link}