Modelle können nicht einmal das Wetter der nächsten Woche genau prognostizieren …
Jetzt komme man nicht mit dem Einwand „Klima ist nicht Wetter“. Das ist banal und dumm. Der Knabe, der sagt, dass „Nahrung nicht Küche ist“, ist ein Nahrungs-Kritiker und von vornherein hochmütig und unausstehlich.
Wie ist es hiermit: Wissenschaft ist keine Semantik.
Wir alle würden nur zu gerne die Zukunft vorhersagen können. Intellektuell, empirisch und rational wissen wir, dass wir das nicht können, aber einige versuchen es dennoch. In ganz Washington, DC, wo ich lebe, gibt es neben den Elite-Intelligenzen, die ihre eigenen Bücher über den in New York beheimateten Acela lesen, zahlreiche Tarotkartenleser und Hellseher, die ihre Dienste als Wahrsager anbieten.
Und wir hören Geschichten. Der Kumpel, der einen guten Aktienkauf tätigte, weil „er sicher war“, dass die Aktie steigen würde. Oder den Knaben, der proklamiert, dass „er wusste, dass die Nationals die World Series* gewinnen würden“. Das ist nicht wahr. Nicht möglich. Nicht einmal logisch zu begründen. Es ist Syntax, nicht Wahrheit.
[*Endspiel um die amerikanische Baseball-Meisterschaft, vergleichbar mit dem Super Bowl im Football. Anm. d. Übers.]
Wir können Entscheidungen für die Zukunft treffen, nicht auf der Grundlage übernatürlicher Intelligenz, sondern auf der Grundlage von Daten. Markttrends und Bilanzen leiten Aktiengeschäfte, aber es gibt keine Garantie, dass der Wert der Aktie steigt. Wären wir nicht alle schon reich, wenn das der Fall wäre? Im Baseball bilden Verletzungen, Rotation und Aufstellung sowie Teamloyalität unsere Leitlinien, aber es gibt keine Garantie, dass unser Team gewinnen wird.
Niemand „wusste“, dass das Wetter dem Start von SpaceX einen Strich durch die Rechnung machen würde, vielmehr zogen Wissenschaftler Daten heran, um einen bestmöglichen guess abzugeben, was Teil der wissenschaftlichen Methodik ist, die wir in der 3. Klasse gelernt haben. Genauso „weiß“ niemand, was in 5, 10, 15 oder 50 Jahren mit der Erde passieren wird im Zuge des Klimawandels. Ich bin es also leid, dazu ständig irgendetwas zu hören.
Und jetzt zur Antwort auf die Frage, bevor Sie sie stellen: nein, es gibt keine Daten, aus denen hervorgeht, dass die Temperaturen der Welt auf ein unbewohnbares Niveau steigen. Es gibt nur Modelle, und Modelle sind sehr, sehr menschlich.
Klimawandel-Modelle sind im Computer generiert und programmiert von voreingenommenen Individuen. Sie basieren nicht auf einem wissenschaftlichen Prozess, sondern auf Prognose auf der Grundlage verfügbarer Daten, die akkurat sein können oder auch nicht. Erinnert man sich noch an das Modell, welches 2,2 Millionen Tote durch das Coronavirus prophezeit hatte?
Whoopsie!
Müll rein, Müll raus – genau wie in jedem anderen, von Computern generierten Szenario. Vielleicht wird eines Tages künstliche Intelligenz tatsächlich intelligent werden und den Programmierer korrigieren, aber derzeit folgt der Computer genau dem vom sehr fehlbaren Menschen geschriebenen Programm.
Daher kommt auch die Empörung über den Kommentar von Kongress-Dame Alexandria Ocasio-Cortez, die da posaunte: „Die Welt wird in 12 Jahren untergehen, wenn wir nicht dem Klimawandel begegnen“. Nicht, weil der Kommentar töricht ist (ist er), nicht weil er falsch ist (ist er), sondern weil er so absichtlich irreführend ist. Es ist ein perfektes Beispiel dafür, wie man eine Spekulation in ein Faktum verwandelt, und das ausschließlich aufgrund des Vorantreibens einer politischen Agenda, die ein einziger Angriff auf meine Brieftasche ist. Es tötet jede Diskussion. Es stößt vernünftige Leute wie mich ab. Es ist kaum sinnvoll, über Klimawandel zu diskutieren, ebenso wie über den Beitrag der Menschheit zu demselben, wenn es überhaupt einen gibt. Und trotzdem, immer mehr politische Maßnahmen und immer mehr Geld des Steuerzahlers wird auf der Grundlage dieser Art von unlogischem Denken ausgegeben.
Klima ist die große Unbekannte, und Politiker und Medien gleichermaßen lieben es, normale Amerikaner bis zum Anschlag zu ängstigen, indem man eine großartige Einsicht in das Morgen vortäuscht, die sie in ihren Sesseln erzittern lässt. Der Klimawandel wird uns töten. Paul Ehrlich sagte in den 1970er Jahren, dass die Überbevölkerung dazu führen wird, dass England im Jahre 2000 nicht mehr existieren wird. Die arme Queen, als ob sie nicht schon genug um die Ohren hätte. Al Gore prophezeite vor 20 Jahren, dass das Arktische Eis längst verschwunden sein sollte – und bekam dafür einen Oskar.
Als ich das letzte Mal hingesehen hatte, ging es sowohl UK als auch dem arktischen Eis wunderbar. Das Aussehen beider ändert sich fortwährend. Das waren eben keine Prognosen. Es waren Modellergebnisse, dazu gedacht, Angst zu erzeugen und eine Agenda voranzutreiben.
Wir können das Wetter noch nicht einmal ein paar Wochen voraussagen. Am 20. März dieses Jahres prophezeite die Washington Post ein „außerordentlich warmes Frühjahr“ in den gesamten USA, und zwar aufgrund von auf Daten basierenden Modellen (Wintertemperaturen, Polarwirbel). Das wurde als Faktum dargestellt. Zeug von der Art ängstigender globaler Erwärmung. Meine Güte.
Einen Monat nach Erscheinen dieses Artikels wies der gleiche Autor in der gleichen Publikation darauf hin, dass die Temperatur in Washington DC schon zwei Wochen lang unter den Mittelwerten gelegen hatte. Das bedeutet, der Untergangs-Artikel konnte nicht einmal 2 Wochen in die Zukunft schauen. Ein paar Tage später räumte man in der gleichen Publikation ein, dass das um 1 bis 2 Grad zu kalte Wetter wahrscheinlich weitergehen werde.
Huh.
Dann wartete die gleiche Washington Post mit einem Artikel auf mit dem Titel [übersetzt] „Außerordentlich kaltes Wetter für Mai kommt heute Nacht daher mit Temperaturen nahe dem Gefrierpunkt und eisigen gefühlten Temperaturen“. Am nächsten Tag schrieb man über den kältesten Tag in Washington seit über einem Jahrzehnt, und dass in Baltimore der kälteste Tag in einem Mai jemals aufgetreten war.
Was schließen wir daraus? Einfach: Der erste Artikel, der Angst über Angst erzeugende Klimawandel-Artikel, basierte auf Modellen (wurde aber als Faktum präsentiert). Die nachfolgenden „Hilfe-ist-das-kalt“-Artikel basierten auf … nun, Tatsachen. Die aber längst nicht so ängstigend und nicht so spaßig daherkommen.
Wird die Welt wegen des Klimawandels zugrunde gehen?. Das weiß ich nicht. Werden die Meere steigen und die Seen überkochen? Ich weiß es nicht. Und auch niemand sonst weiß es.
Übersetzt von Chris Frey EIKE
————————————-
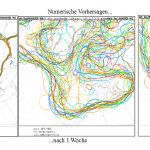
Erklärung des Bildes oben:

Gezeigt ist die numerische Vorhersage des amerikanischen GFS-Modells vom Sonnabend, dem 6. Juni 2020 für 1 Tag (links), 1 Woche (Mitte) und 2 Wochen rechts. Die eingehenden Daten weisen in riesigen Gebieten große Lücken auf, z. B. über den Ozeanen, und müssen dort extrapoliert werden. Fehler sind dabei unvermeidlich, selbst wenn sie nur gering sind. Um abzuklopfen, wie zuverlässig eine solche Simulation ist (von Computern, die nicht einmal das Wort „Wetter“ buchstabieren können, wenn man es ihnen nicht sagt!), verändert man den Anfangszustand künstlich minimal und lässt die Simulation immer wieder laufen – in diesem Beispiel 10 mal.
Den Verlauf der Linien muss der Meteorologe dann in eine Wettervorhersage „übersetzen“. Je enger die Linien beieinander liegen, umso genauer die Prognose. Nach 1 Woche liegen die Linien schon deutlich auseinander, aber eine allgemeine Tendenz ist noch erkennbar – jedoch keine Einzelheiten mehr! Nach 2 Wochen gleicht der Verlauf der Linien einem Kunstwerk eines Kindergarten-Kindes. Da kann man zwar noch raten, aber nichts mehr prognostizieren. 2Wochen! Und: Jeder einzelne Verlauf ist aus der Sicht des Ausgangstages gleich wahrscheinlich!
Dipl.-Met. Christian Freuer
