
Clyde Spencer
Ausgelöst durch die jüngsten Gastbeiträge bei WUWT nebst den zugehörigen Kommentaren beschloss ich, etwas zu tun, was ich schon zu lange auf die lange Bank geschoben habe – nämlich mich mit dem zu befassen, was das IPCC zur Modellierung des Klimas zu sagen hat. Hier folgen meine Bemerkungen zu den meiner Ansicht nach bedeutendsten Aussagen des IPCC, zu finden in FAQ 9.1. Darin wird die Frage gestellt „Werden Klimamodelle besser, und wie würden wir das mitbekommen?“
Im AR 5 des IPCC heißt es unter FAQ 9.1 (Seite 824):
Die Komplexität von Klimamodellen … hat seit dem AR 1 aus dem Jahr 1990 substantiell zugenommen. In dieser Hinsicht sind also gegenwärtige Modelle des Erdsystems deutlich ,besser‘ als die Modelle von damals.
Sie definieren „besser“ explizit als ,komplexer‘. Was die Politiker jedoch wissen müssen ist, ob diese Prophezeiungen präziser und zuverlässiger sind! Das heißt, sind sie überhaupt brauchbar?
Bei FAQ 9.1 heißt es weiter:
Ein wichtiger Gedanke ist, dass die Modellgüte nur evaluiert werden kann relativ zu Beobachtungen aus der Vergangenheit, wobei man die natürliche interne Variabilität berücksichtigen muss.
Dies stimmt nur dann, wenn die Modelle so angepasst werden, dass sie zum Wetter der Vergangenheit passen, besonders hinsichtlich Temperatur und Niederschlag. Allerdings ist dieses Pseudo-Modellverhalten kaum besser als das Anpassen einer Kurve mittels eines Polynoms höherer Ordnung. Was man tun sollte ist, den Verlass auf historische Daten zu minimieren, wobei man eher Grundsätzen folgen sollte als dem, was derzeit gemacht wird, nämlich eine Projektion zu simulieren und dann 5 bis 10 Jahre warten, um abzuschätzen, wie gut die projizierte Vorhersage zu tatsächlichen zukünftigen Temperaturen passt. So wie man es derzeit macht – trotz der Anwendung von Grundsätzen – dürfte es kaum besser sein als die Verwendung eines neuralen ,Black Box‘-Netzwerkes für Vorhersagen wegen der Stützung auf das, was Ingenieure „Toffee-Faktor“ [fudge factors] nennen bei der Anpassung an die Historie.
Weiter bei FAQ 9.1:
Um Vertrauen in die Zukunfts-Projektionen derartiger Modelle zu haben, muss das historische Klima – nebst dessen Variabilität und Änderung – gut simuliert sein.
Offensichtlich ist, dass falls die Modelle das historische Klima nicht gut simulieren man kein Vertrauen in ihre Fähigkeit zu Vorhersagen setzen würde. Allerdings reicht die Anlehnung an die Historie nicht aus, um zu garantieren, dass Projektionen korrekt sind. Polynom-Anpassungen der Daten kann hohe Korrelations-Koeffizienten haben, sind jedoch dafür bekannt, in das Nirwana zu entfleuchen, wenn man über die Datensequenz hinaus extrapoliert. Darum sage ich oben, dass der Wahrheits-Test darin besteht, die Modelle tatsächlich die Zukunft vorhersagen zu lassen. Ein anderes Verfahren, das man anwenden könnte wäre, die Modelle nicht an alle historischen Daten anzupassen, sondern nur an die Daten aus vorindustrieller Zeit oder vor dem Zweiten Weltkrieg. Dann lasse man sie laufen und begutachte, wie gut sie die zweite Hälfte des vorigen Jahrhunderts simulieren.
Eines der Probleme bei der Anpassung an historische Daten ist, dass falls die bestehenden Modelle nicht alle Faktoren enthält, welche das Wetter beeinflussen (und das ist fast mit Sicherheit der Fall), dann wird der Einfluss der fehlenden Parameter ungeeignet durch andere Faktoren approximiert. Das heißt, falls es in der Vergangenheit eine ,Störung beim Forcing‘ unbekannter Natur und Größenordnung gegeben hat und man die Daten entsprechend korrigiert, wäre es erforderlich, die Variablen zu korrigieren, die in dem Modellen enthalten sind. Können wir sicher sein, dass wir alle exogenen Inputs bzgl. Klima ausgemacht haben? Können wir sicher sein, dass alle feedback loops mathematisch korrekt sind?
Unbequemerweise wird in Kasten 9.1 (Seite 750) angemerkt:
Zumindest für ein Modell wurde gezeigt, dass der Anpassungsprozess nicht notwendigerweise einen einzelnen, einheitlichen Satz von Parametern für ein gegebenes Modell ergibt, sondern dass verschiedene Kombinationen von Parametern gleich plausible Modelle ergeben können (Mauritsen et al. 2012)
Diese Modelle sind so komplex, dass es unmöglich ist vorherzusagen, wie eine Unendlichkeit von Parameter-Kombinationen die verschiedenen Outputs beeinflussen könnten.
Die Art der in modernen Daten verfügbaren meteorologischen Details steht für historische Daten nicht zur Verfügung, besonders in der Zeit vor dem 20. Jahrhundert! Folglich würde es eine voreilige Schlussfolgerung sein, dass fehlende Forcing-Informationen auf andere Faktoren übertragen werden, die in den Modellen sind. Klarer beschrieben: wir kennen die Zeitpunkte von fast allen Vulkanausbrüchen in der Vergangenheit. Allerdings kann die Dichte der vulkanischen Asche in der Atmosphäre im besten Falle nur geschätzt werden, während die Dichte von Asche und Aerosolen bei aktuellen Ausbrüchen gemessen werden kann. Historische Eruptionen in dünn bevölkerten Gebieten können auch nur Spekulation sein auf der Grundlage eines plötzlichen Rückgangs der globalen Temperaturen zumindest ein paar Jahre lang. Wir haben lediglich qualitative Schätzungen bzgl. außerordentlicher Ereignisse wie z. B. das Carrington-Ereignis, ein koronaler Massenauswurf im Jahre 1859. Wir können uns nur fragen, was alles eine solche massive Injektion von Energie in die Atmosphäre anrichten kann.
Jüngst wurden Bedenken laut, wie der Ozon-Abbau das Klima beeinflussen könnte. Tatsächlich waren Einige so kühn zu behaupten,, dass das Montreal-Protokoll einen unerwünschten Klimawandel verhindert hat. Wir können nicht sicher sein, dass einige Vulkane wie etwa der Mount Katmai in Alaska keinen signifikanten Effekt auf die Ozonschicht hatten, bevor wir überhaupt von Variationen des Ozons wussten. Dieser Vulkan ist bekannt für seine anomalen Emissionen von Salzsäure und Fluorwasserstoff (siehe Seite 4). Weiteres hierzu findet man hier.
Fortsetzung von FAQ 9.1:
Unvermeidlich machen sich einige Modelle hinsichtlich bestimmter Klima-Variablen besser als andere, aber kein Modell zeichnet sich eindeutig als das ,insgesamt beste Modell‘ aus.
Dies liegt zweifellos daran, dass die Modellierer unterschiedliche Hypothesen hinsichtlich Parametrisierungen zugrunde legen, und die Modelle werden an die Variable ihres Interesses angepasst. Dies zeigt, dass die Anpassung die Grundprinzipien außer Kraft setzt und die Ergebnisse dominiert!
Meine Vermutung wird gestützt durch die nachfolgende Anmerkung in FAQ 9.1:
…Klimamodelle basieren in erheblichem Umfang (Hervorhebung von mir [=dem Autor]) auf verifizierbaren physikalischen Grundsätzen und sind in der Lage, bedeutende Aspekte von externen Forcings in der Vergangenheit zu reproduzieren.
Man würde denken, dass dieses Anpassen eine erhebliche Schwäche ist bei den gegenwärtigen Modellierungs-Bemühungen zusammen mit der Notwendigkeit, Energie-Austauschprozesse zu parametrisieren (Konvektion und Wolken), welche räumlich zu klein sind, um direkt modelliert zu werden. Anpassen ist der ,Elefant im Raum‘, der kaum einmal beachtet wird.
Die Autoren von Kapitel 9 räumen in Box 9.1 (Seite 750) ein:
…die Notwendigkeit der Modellanpassung könnte die Modell-Unsicherheit zunehmen lassen.
Verschlimmert wird die Lage durch die Anmerkung in diesem gleichen Abschnitt (Box 9.1, Seite 749):
Mit sehr wenigen Ausnahmen beschreiben die Modellierer nicht detailliert, wie sie ihre Modelle anpassen. Daher ist eine vollständige Liste von Widersprüchen zu Beobachtungen, an welche ein bestimmtes Modell angepasst wird, allgemein nicht verfügbar.
Und schließlich stellen die Autoren eindeutig in Frage, wie das Anpassen den Zweck der Modellierung beeinflusst (Box 9,1, Seite 750):
Die Erfordernis von Anpassungen wirft die Frage auf, ob Klimamodelle für Klimaprojektionen der Zukunft überhaupt brauchbar sind.
Ich denke, dass es wichtig ist anzumerken, dass sich vergraben im Kapitel 12 des AR 5 (Seite 1040) das folgende Statement findet:
Insgesamt gesehen gibt es derzeit kein allgemein anerkanntes und robustes formales Verfahren, um quantitative Schätzungen der Unsicherheit zu liefern bzgl. zukünftiger Änderungen aller Klimavariablen … „
Dies ist wichtig, weil es impliziert, dass die unten gezeigten quantitativen Korrelationen nominelle Werte sind ohne Verankerung in inhärenter Unsicherheit. Das heißt, falls die Unsicherheiten sehr groß sind, dann sind die Korrelationen selbst mit großen Unsicherheiten behaftet und sollten zurückhaltend aufgenommen werden.
Auch das folgende Zitat sowie die nachfolgende Illustration aus FAQ 9.1 gilt dem Thema Zuverlässigkeit:
Ein Beispiel von Änderungen der Modellgüte mit der Zeit wird in FAQ 9.1 gezeigt und illustriert die stattfindende, wenn auch mäßige Verbesserung (Hervorhebung von mir [=dem Autor]).
Allgemein sollte man eine hohe, nicht lineare Korrelation zwischen Temperatur und Niederschlag erwarten. In Wüsten regnet oder schneit es nicht viel, ebenso wie an den Polen (effektiv Kältewüsten). Warme Gebiete, also z. B. die Tropen, sind gekennzeichnet durch gewaltige Verdunstung aus den Ozeanen und Feuchtigkeitsanreicherung durch die Vegetation. Sie stellen also gewaltige niederschlagbare Mengen von Wasserdampf zur Verfügung. Daher bin ich kaum überrascht, dass die folgenden Graphiken eine höhere Korrelation zwischen Temperatur und deren räumlicher Verteilung zeigen als für Niederschlag und dessen räumlicher Verteilung. Bzgl. Temperatur werden Gebiete gezeigt, in denen die modellierte Temperatur höher ist als die gemessenen Temperaturen, dann muss es aber auch Gebiete geben, in denen es kühler als gemessen ist, um den Anpassungen an das globale Temperaturmittel zu genügen. Daher bin ich nicht vollständig überzeugt von Behauptungen hoher Korrelationen zwischen Temperaturen und der räumlichen Verteilung. Könnte es sein, dass die „Oberflächen-Temperaturen“ auch die Wassertemperatur der Ozeane enthalten, und weil die Ozeane über 70% der Erdoberfläche bedecken und nicht die Temperaturextreme des Festlands aufweisen, und dass daher die Temperaturverteilung stark durch Wassertemperaturen gewichtet sind? Das heißt, würden die Korrelations-Koeffizienten fast genauso hoch sein als wenn man ausschließlich Temperaturen auf dem Festland heranzieht?
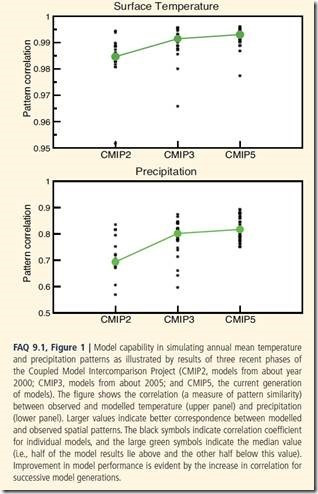
Bildinschrift: FAQ 9.1, Abbildung 1: Fähigkeit der Modelle, die jährliche mittlere Temperatur und die Verteilung von Niederschlag zu simulieren, illustriert durch die Ergebnisse von drei jüngeren Phasen der CMIP-Modelle (CMIP2 um das Jahr 2000, CMIP3 aus dem Jahr 2005 und CMIP5, die jetzige Modellgeneration). Die Abbildung zeigt die Korrelation zwischen gemessener und modellierter Temperatur (oben) und des Niederschlags (unten). Größere Werte deuten auf eine bessere Korrespondenz zwischen modellierten und beobachteten räumlichen Verteilungen. Die schwarzen Symbole deuten auf Korrelations-Koeffizienten individueller Modelle, und die großen grünen Symbole zeigen den Median-Wert (d. h. die Hälfte der Modellergebnisse liegt über, die andere Hälfte unter diesem Wert. Die Verbesserung des Modellverhaltens wird deutlich durch die Zunahme der Korrelation bei aufeinanderfolgenden Modell-Generationen.
Man sollte beachten, dass die behaupteten Korrelations-Koeffizienten sowohl für CMIP3 als auch für CMIP5 implizieren, dass lediglich 65% des Niederschlags vorhergesagt werden können durch den Ort oder die räumliche Verteilung. Falls Verteilungen des Niederschlags so schlecht erklärt sind im Vergleich zur mittleren Temperatur, gewinne ich kein Vertrauen, dass regionale Temperaturverteilungen Korrelations-Koeffizienten aufweisen, die so hoch sind wie das globale Mittel.
Der AR 5 des IPCC steht hier.
*Intergovernmental Panel on Climate Change, Fifth Assessment Report: Working Group 1; Climate Change 2013: The Physical Science Basis: Chapter 9 – Evaluation of Climate Models
Link: https://wattsupwiththat.com/2017/09/27/frequently-asked-questions-9-1-a-critique-2/
Übersetzt durch Chris Frey EIKE


Die Modelliererei des Klimageschehens kann mit einem Wort beschrieben werden: Scharlatanierie.
… und mit einem zweiten Wort:
Computerspiel
Man betrachte die Modelle als das, was sie tatsächlich sind: Eine grobe Abbildung der unbekannten Realität. Mit einer horizontalen Auflösung von 1,875° und 47 Schichten in unseren Breiten ca. 110*64 km. Lübeck würde dann das Wetter im Rechteck zwischen Kiel, Hamburg und Wismar repräsentieren. Die Modellierer kennen natürlich die Defizite. Damit es aber Geld von der Politik gibt – unabhängige universitäre Grundlagenforschung gibt es in Deutschland nicht mehr – werden die von der Politik gewünschten Ergebnisse geliefert. Der sog. „Dieselskandal“ ist auch solch ein Produkt aufgrund politischer (völlig absurder und unbegründeter Vorstellungen) Wünsche, wo irgendwelche Manager nicht erst die Ingenieure gefragt haben, ob etwas machbar sei, wobei das Entscheidungskriterium innerhalb des Konzerns die Kosten waren, also wie groß der Zusatztank incl. Verbrauch für Harnstoff sein durfte.
Deshalb fabrizieren die Modelle ja auch keine Vorhersagen sondern Projektionen der möglichen Zukunft. Die wird dann auf eine „Mitteltewmperatur“ (oder andere Parameter) reduziert, wobei dann das Phänomen zu erkennen ist, daß das Mittel zwar stimmt, aber die dazugehörigen Minima und Maxima nicht.
Wie funktioniert jetzt die Politik? Eine Margariunespezialistin erläßt Freiheitseinschränkungen für die Bürger, weil das schon immer deren Ziel als Gutmenschin des real existierenden Sozialismus war, äh deutscher Sozialdemokratie …
Die Sozialdemokratie ist tot. Nunmehr ist das die Spezialdemokratie mit der Spezialdemokratischen Partei Deutschlands.
Tacheles reden:
Die Bundesrepublik Deutschland wandelt sich langsam aber sicher in eine Deutsche Demokratische Republik.
Wenn die glauben, dass Computer das Klima simulieren/regulieren können, dann bilden die sich auch ein, dass Computer bei einer neuen Planwirtschaft weiterhelfen. Die grünen Simulationen liefern ja jetzt schon genug Öko-Strom, und das Klima…. ja das schaffen wir auch noch.
Bei Honecker gab’s keine Computer, der musste ja scheitern, nicht wahr?